《The Book of Why》引言“Mind over Data”深度讲解
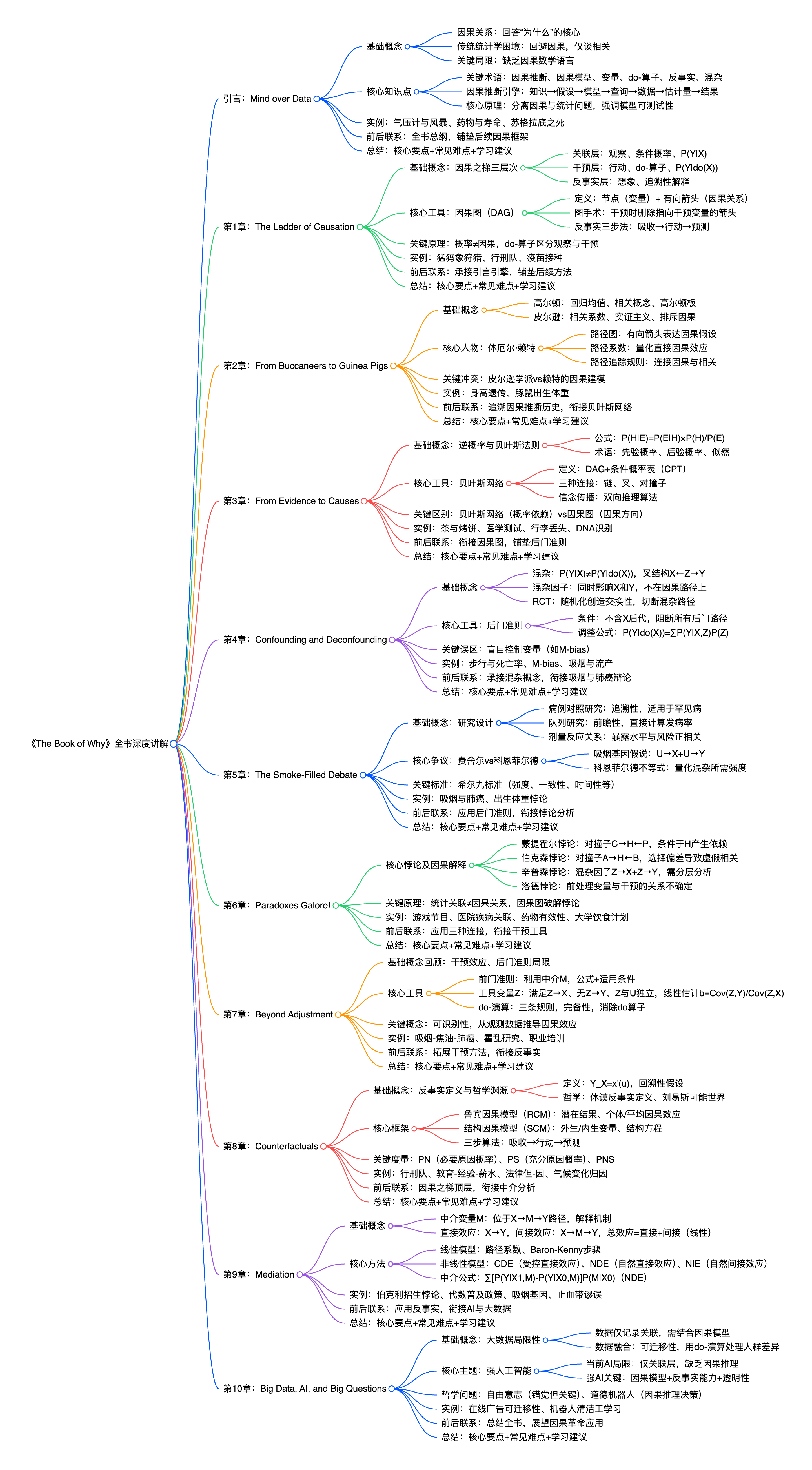
引言:为什么我们需要因果思维?
本章开篇即点明核心:我们正处在一场科学变革之中——因果推断。这场变革的核心,是让科学能够严谨地回答那些关于“为什么”的问题,而不仅仅是“是什么”或“有多少”。
1. 基础概念:从日常困惑到科学难题
- 核心问题: 我们每天都会问“为什么”,比如“为什么我的头痛好了?”、“为什么这家公司的销量上升了?”。这些问题都涉及因果关系。
- 传统科学的困境: 尽管人类天生就具备因果思维,但传统科学,尤其是统计学,长期以来却刻意回避谈论因果关系。统计学教科书上最著名的一句话就是:“相关关系不等于因果关系”。这句话固然正确(例如,公鸡打鸣与太阳升起相关,但公鸡不打鸣,太阳照常升起),但它只告诉你什么不是,却没有告诉你什么是。
- 根本原因: 科学家缺乏一套数学语言来表达因果关系。用传统的代数方程(如
B = kP表示气压和气压计读数的关系),你可以随意改写方程(P = B/k),但数学上无法表达“是气压导致气压计变化,而不是反过来”这种强烈的因果信念。这种语言上的缺失,导致因果问题长期被排除在严谨的科学讨论之外。
2. 核心知识点:因果推断的框架
这一章的核心是引入了一套全新的、处理因果关系的思维框架和工具。
2.1 关键术语与定义
- 因果推断 (Causal Inference):一门旨在从数据、假设和知识中,得出关于因果关系(如“X是Y的原因”)的科学。它试图回答那些“为什么”和“如果…会怎样”的问题。
- 因果模型 (Causal Model):对现实世界因果过程的一种简化表示。它编码了我们关于“什么导致什么”的现有知识。模型的形式可以是:
- 因果图 (Causal Diagram):用节点(变量)和箭头(因果关系)构成的点-箭头图,直观地表示变量之间的依赖关系。例如,
吸烟 → 肺癌。 - 结构方程 (Structural Equations):用数学方程描述变量之间的函数关系。例如,
肺癌发生率 = f(吸烟, 遗传因素)。
- 因果图 (Causal Diagram):用节点(变量)和箭头(因果关系)构成的点-箭头图,直观地表示变量之间的依赖关系。例如,
- 变量 (Variable):我们感兴趣的、可以取不同值的量。例如,“是否服药”(是/否)、“血压”(数值)、“寿命”(年数)。
do-算子 (do-operator):这是因果推断中最重要的符号创新,用do(X)表示。它代表了对系统进行干预,即强制将变量X设为某个值x,而不仅仅是被动观察到X为x。- 观察 (Seeing):
P(L | D),即我们看到某人服用了药物 (D),他的寿命 (L) 的概率分布。问题在于,服药的人可能本身身体就更好,所以这个概率可能不是由药物导致的。 - 干预 (Doing):
P(L | do(D)),即我们强制某人服用药物 (D),他的寿命 (L) 的概率分布。这消除了自我选择带来的偏差,这才是我们真正想要的药物因果效应。 - 例子:气压计与风暴。看到气压计下降 (
P(风暴 | 看到气压计下降)) 会增加风暴的概率。但是,如果我们强制让气压计下降 (do(气压计下降)),比如用真空泵抽气,这绝不会引起风暴。do-算子完美地区分了“观察”和“干预”。
- 观察 (Seeing):
- 反事实 (Counterfactual):这是因果推理的最高层级。它问的是“如果当初…会怎样?”。
- 定义:想象一个与事实相反的世界,并在这个世界中推断结果。
- 例子:“乔服了药后死了。我想知道,如果他没有服药,他还会活着吗?” (
P(乔活着 | 乔服了药, 乔死了, do(乔未服药)))。这个问题无法仅通过观察数据回答,因为它涉及一个没有发生的、反事实的世界。
- 混杂 (Confounding):一个同时影响原因 (
X) 和结果 (Y) 的变量,导致X和Y之间出现虚假关联的现象。- 例子:冰激凌销量与犯罪率。两者高度相关,但真正的原因是第三个变量——天气炎热。天气热既导致人们吃更多冰激凌,也可能导致人们情绪烦躁、户外活动增多,从而犯罪率上升。天气就是一个混杂因子。
2.2 核心原理:因果推断引擎
本章提出了全书最核心的蓝图:因果推断引擎 (图 I.1)。这个引擎清晰地展示了如何将知识、假设和数据结合起来,以严谨的方式回答因果问题。
Mermaid 概念关系图:
(隐含的,如经验、常识)] --> A2[2 显性假设
(基于知识提炼)] A2 --> A3[3 因果模型
(如因果图)] Q["5 因果查询
(如 P(L|do(D)))"] --> Engine D[7 数据
(观察数据)] --> Engine end subgraph 因果推断引擎 Engine{推理引擎} --> T[6 可计算估计量
(Estimand,数学公式)] T --> E[8 估计值
(Estimate,计算结果)] end subgraph 模型测试与修正 A3 --> Test[4 模型的可检验蕴涵] Test -- 数据不符合模型预测 --> A3 Test -- 数据符合模型预测 --> Engine end subgraph 输出 E --> Ans[9 对查询的答案
(如“药物将寿命延长30%”)] end style Engine fill:#f9f,stroke:#333,stroke-width:2px style T fill:#ccf,stroke:#333 style E fill:#ccf,stroke:#333 style Ans fill:#cfc,stroke:#333
引擎的组成部分解释:
输入部分:
- 1. 知识 (Knowledge):你头脑中已有的全部信息,包括经验、文化、先前的研究等。它是所有假设的来源,但在模型中通常是隐含的。
- 2. 假设 (Assumptions):从背景知识中提炼出来的、明确陈述的科学信念。例如,“我们认为年龄同时影响是否服药和寿命”。这些假设必须明确化。
- 3. 因果模型 (Causal Model):将假设以一种可计算的形式表达出来。本书最推崇的形式是因果图。例如,用箭头连接“年龄”、“服药”、“寿命”。
- 4. 模型的可检验蕴涵 (Testable Implications):因果模型本身会推导出一些数据上的特征。例如,模型可能预测“年龄”和“寿命”在统计上是相关的。如果数据与这个预测不符,就说明我们的模型可能是错的,需要修正。
- 5. 因果查询 (Causal Query):我们真正想知道的因果问题,必须用因果语言表达。例如,“如果强制所有人都服药,他们的平均寿命会是多少?”,即
P(L | do(D))。 - 7. 数据 (Data):我们收集到的观察数据。注意,数据本身是“愚蠢”的,它只包含关联信息,如
P(L|D)、P(L|D, Z)。
核心处理:
- 6. 可计算估计量 (Estimand):这是引擎的智慧所在。它基于因果模型,将我们的因果查询(含
do)转化为一个只包含标准统计量的数学公式。这个公式就像一个食谱,告诉我们如何用数据来烹饪出我们想要的因果答案。例如,P(L|do(D))可能被转化为∑ P(L|D, Z) × P(Z)。这一步是整个因果推断的关键。 - 8. 估计值 (Estimate):将实际数据代入“可计算估计量”这个公式中,计算出的具体数值结果。例如,“药物将寿命延长了30%”。
- 6. 可计算估计量 (Estimand):这是引擎的智慧所在。它基于因果模型,将我们的因果查询(含
输出:
- 9. 答案 (Answer):最终的答案,它回答了我们最初的因果查询,并且会反过来丰富我们的背景知识。
这个引擎的伟大之处在于:
- 分离了因果问题与统计问题:
do-算子让我们能精确表达因果问题;可计算估计量则将因果问题转化为统计问题。 - 明确了数据的局限性:数据只在最后一步(估计值)才被使用。如果模型告诉我们某个查询是不可回答的,那么收集再多数据也没用。
- 强调了模型的可测试性:模型不是凭空捏造的,它必须能与数据对话,接受检验和修正。
3. 实例辅助理解
概念:因果图 vs. 混杂
- 问题:评估某种药物 (
D) 对寿命 (L) 的效果。 - 因果图:我们可以画一个图,里面有
D(服药与否)、L(寿命),还有一个可能的变量Z(病情严重程度)。箭头可以这样画:Z → D(病情严重的人更可能服药),Z → L(病情严重的人本身寿命就可能更短)。这就是一个典型的混杂结构。 do-算子:P(L|do(D))就是我们想要的。它问的是:“如果我把所有人都强制服药,他们的寿命会怎样?” 而观察数据P(L|D)反映的是“那些自愿服药的人(他们可能病情更重),他们的寿命如何”。- 可计算估计量:根据因果图,我们可以推导出
P(L|do(D))的估计量可能是∑ P(L|D, Z) P(Z)。这个公式的意思是,我们分别在病情严重 (Z=严重) 和病情不严重 (Z=不严重) 的人群中,比较服药者和未服药者的寿命,然后根据总人口中不同病情程度的比例进行加权平均。这就在数学上剔除了Z的混杂影响。
- 问题:评估某种药物 (
概念:反事实
- 问题:苏格拉底是一名七十岁的囚犯,他被判处服毒。他喝下了毒药,然后死了。毒药对他来说是致命的吗?
- 观察:
P(死亡 | 服毒, 苏格拉底)= 1。但这不能回答我们的问题。 - 反事实查询:“如果苏格拉底没有服毒,他还会死吗?” 即
P(死亡 | 服毒, 死亡, do(未服毒))。 - 推理:我们基于一个因果模型(毒药导致死亡,但七十岁的人也可能自然死亡)来推断。在这个反事实世界里,苏格拉底没有服毒,但考虑到他的年龄,他仍然有一定概率自然死亡。通过模型,我们可以计算出这个概率,从而判断“服毒”是否是导致他死亡的必要原因。
4. 前后联系,构建知识网络
- 与后文的联系:这一章是全书的总纲。
- 第一章 (The Ladder of Causation):将详细介绍本章提到的观察、干预、反事实这三个层次,并形象地称之为“因果之梯”。
- 第二章 (From Buccaneers to Guinea Pigs):将深入历史,解释为什么统计学在过去一个世纪里回避因果关系,以及像休厄尔·赖特这样的先驱是如何逆流而上的。
- 第三章 (From Evidence to Causes):将介绍贝叶斯网络,它是因果图的基础,并展示了如何用概率语言进行推理。
- 第四章 (Confounding and Deconfounding):将详细讲解混杂是什么,以及如何利用因果图(如后门准则)来消除混杂,这正是因果推断引擎中“可计算估计量”推导的关键。
- 第七、八、九章:将分别深入探讨干预、反事实和中介作用,这些都是本章提出的因果推断引擎的具体应用和深化。
- 第十章 (Big Data, Artificial Intelligence, and the Big Questions):将回到本章开头提出的问题——数据是“愚蠢”的,并展望因果革命如何为人工智能和“大数据”注入真正的智能。
5. 本章总结与重点
核心要点
- 数据是“愚蠢”的:数据本身只能告诉我们相关关系,无法回答因果问题。因果关系必须由人的思维赋予。
- 因果模型是核心:要得到因果答案,必须先有一个因果模型(如因果图),它承载了我们关于世界如何运作的假设。
- 区分“看到”和“做到”:
do-算子是将因果问题(关于“做”)与统计问题(关于“看”)区分开来的关键数学工具。 - 反事实是最高层级的因果思维:回答“如果…会怎样”的能力是人类智能的核心,也是因果推断的终极挑战。
- 因果推断引擎是方法论框架:它清晰地展示了如何将知识、假设、模型和数据结合在一起,以系统化、可检验的方式回答因果问题。
常见难点
- 混淆“观察”与“干预”:初学者容易混淆
P(Y|X)和P(Y|do(X))。要时刻记住,前者是被动看,后者是主动做。 - 对“可计算估计量”的理解:难以理解为什么可以把一个含
do的问题变成不含do的公式。关键是要理解,这个转化过程依赖于因果模型中的假设(如后门准则)。它不是一个纯粹的数学变换,而是因果知识驱动的逻辑推导。 - 因果图的力量:可能会觉得画几个箭头过于简单。但正是这种简单的图形语言,让我们能够清晰地表达复杂的因果假设,并推导出如何进行数学计算。它是连接定性知识(箭头)和定量数据(统计)的桥梁。
学习建议
- 带着问题阅读:在阅读后续章节时,不断回想本章的“因果推断引擎”流程图。你遇到的每个新概念、新方法(如后门准则、工具变量),都可以尝试将其放入这个引擎的框架中,思考它属于哪一步(是模型?是可计算估计量?是处理哪种查询?)。
- 动手画图:遇到一个因果问题时,尝试自己动手画出因果图。哪怕是你生活中的小事,比如“为什么我昨晚没睡好?”,都可以试着画出可能的因果因素(喝了咖啡、压力大、邻居吵闹等)。
- 理解
do的本质:将do理解为一场思想实验。do(X=x)就是问:“如果这个世界被修改了,以至于X被强制设定为x,那么Y会变成什么?” 这种“修改世界”的视角是理解因果推断的关键。
希望这份详细的讲解能帮助你打下坚实的基础,顺利开启《The Book of Why》的探索之旅。
《The Book of Why》第1章“The Ladder of Causation”深度讲解
引言:因果之梯的起源
本章以《圣经》中亚当与夏娃的故事开篇,引出一个深刻的洞察:人类在获得知识的同时,也获得了因果解释的能力。当我们问“为什么”时,我们已经在寻求因果链条上的答案。朱迪亚·珀尔将这种能力形式化为因果之梯,它清晰地划分了人类处理因果关系的三个认知层次。本章是全书的理论基石,它定义了因果思维的基本框架,并为后续章节探讨具体方法奠定了概念基础。
1. 从基础概念开始:因果之梯的三级台阶
因果之梯是一个三层结构,每一层都对应着一种处理世界信息的能力。我们由低到高逐一攀登。
第一层:关联 (Association)
- 定义:通过观察发现规律。当我们观察到一件事与另一件事同时或相继发生时,我们便识别出了关联。
- 核心问题:“如果我看到了……,会怎样?” (What if I see …?)
例如:看到某人买了牙膏,他也会买牙线的概率有多大? - 典型操作:观察、被动收集数据、计算条件概率。
数学表达:P(牙线 | 牙膏),即在看到购买牙膏的条件下购买牙线的概率。 - 认知主体:许多动物和当前的大多数机器学习系统(包括深度神经网络)都处于这一层。它们能发现模式,但无法理解模式背后的原因。
- 局限性:关联不等于因果。公鸡打鸣与太阳升起高度相关,但打鸣并不会导致日出。
第二层:干预 (Intervention)
- 定义:主动改变世界,并预测改变后的结果。
- 核心问题:“如果我们做了……,会怎样?” (What if we do …?)
例如:如果我们把牙膏价格提高一倍,牙线的销量会如何变化? - 典型操作:执行实验、施加策略、比较不同干预下的结果。
数学表达:P(牙线 | do(牙膏价格翻倍))。这里的do操作符是珀尔引入的关键符号,它表示我们强制改变一个变量,而不仅仅是观察到它。 - 认知主体:早期人类(如计划猛犸象狩猎)以及能够有意使用工具的生物。干预要求我们拥有一个因果模型,能够预测行动带来的变化。
- 关键区分:
P(Y|X)(看到)与P(Y|do(X))(做到)是完全不同的。气压计读数下降 (P(风暴|看到气压计下降)) 能预测风暴,但强制让气压计下降 (do(气压计下降)) 却不会引发风暴。
第三层:反事实 (Counterfactuals)
- 定义:想象一个与事实相反的世界,并在这个世界中推断结果。这是人类独有的高级认知能力。
- 核心问题:“如果我当时做了不同的事,会怎样?” (What if I had done …?) 以及核心的“为什么?”
例如:我的头痛好了,如果我没吃阿司匹林,头还会痛吗? 这是追溯性解释。 - 典型操作:在心理模型中回溯过去,修改一个条件,然后重新模拟结果。
数学表达:需要用到反事实条件,如P(Y_{X=0} = 1 | X=1, Y=1),表示在观察到某人服药且死亡的情况下,假如他未服药他会死亡的概率。 - 认知主体:只有人类(也许还包括一些高等动物)能够稳定地进行反事实推理。这是道德责任、后悔、学习和科学发现的根源。
- 重要性:反事实是连接观察与干预的桥梁,它让我们能从历史中学习,评估责任,理解机制。
2. 核心工具:因果图 (Causal Diagrams)
为了在数学上操作这三个层次,我们需要一种语言来描述因果关系。珀尔引入了因果图。
- 定义:由节点和箭头组成的有向无环图 (DAG, Directed Acyclic Graph)。每个节点代表一个变量,箭头表示直接的因果影响。
- 构建原则:箭头应指向“听命于”谁的方向。例如,
X → Y表示Y的取值会“倾听”X的变化。 - 基本功能:因果图以一种极其直观的方式,编码了我们对世界因果结构的假设。
2.1 关键概念与符号
- 变量 (Variable):我们研究的对象,可以是真/假(如行刑队员是否开枪)、数值(如剂量)、或类别。
- 因果箭头 (Causal Arrow):
A → B表示 A 是 B 的直接原因。改变 A 会直接导致 B 的变化。 - 路径 (Path):图中连接两个变量的任意序列。
- 混杂 (Confounding):在后续章节会详述,但在本章中我们已看到,关联可能由共同原因(混杂因子)产生,如图中的
Z → X和Z → Y会导致X和Y产生非因果的相关性。
2.2 因果图如何帮助我们攀登因果之梯
因果图不仅仅是一张静态图画,它是进行因果推理的“手术台”。关键在于,对于不同的因果问题,我们可以对图进行不同的修改。
- 关联层 (观察):我们只需观察图中的数据。例如,在行刑队图中(图1.4),我们看到囚犯死亡,可以推断出上尉下达了命令,因为这是图中因果链条的必然结果。
- 干预层 (行动):当我们问“如果我们强制让某件事发生,会怎样?”时,我们需要对因果图进行手术。
- 图手术 (Graph Surgery):删除所有指向被干预变量(如让士兵 A 开枪)的箭头。这相当于将变量从它的原因中“解放”出来,只受我们的干预影响。
- 例子:在行刑队例子中(图1.5),如果我们强制让士兵 A 开枪 (
do(A=1)),那么我们就删除了从“上尉命令”指向 A 的箭头,然后将 A 强制设为真。然后我们沿着剩余的箭头推理,发现囚犯仍然会死(因为 A 直接开枪)。但此时,我们不再能推断上尉下了命令(因为箭头被删了),士兵 B 也没有开枪。
- 反事实层 (想象):当我们问“如果当初…会怎样?”时,我们需要结合观察事实和假设的干预。
- 三步法:
- 吸收 (Abduction):用观察到的事实(如囚犯已死)来更新我们对模型中未观察因素(如每个士兵的可靠程度)的信念。
- 行动 (Action):对因果图进行手术,执行反事实假设(如让士兵 A 不开枪)。
- 预测 (Prediction):在修改后的模型中,根据更新后的信念,计算出结果。
- 例子(图1.6):我们观察到囚犯死了,且我们知道士兵 A 实际上开了枪。现在问“如果士兵 A 没开枪,囚犯还会死吗?”
- 第一步(吸收):因为观察到死亡,我们推断上尉一定下了命令(否则没人开枪),且士兵 B 一定开了枪(假设他们服从命令且枪法准)。
- 第二步(行动):删除指向 A 的箭头,并设
A=false。 - 第三步(预测):在新模型中,上尉的命令依然存在(从观察中得知),士兵 B 依然会开枪(因为他没被干预),所以囚犯仍然会死。结论:A 的不开枪不会改变结果。
- 三步法:
3. 概念关系图
以下 Mermaid 图清晰地展示了因果之梯的三个层次及其核心特征、问题、与因果图的关系:
What if I see?] Level1 --> Op1["观察
P(Y|X)"] Level1 --> Eg1[例:看到牙膏→牙线概率] Level2 --> Q2[“如果我做...?”
What if I do?] Level2 --> Op2["干预 do(X)
图手术(删除入箭)"] Level2 --> Eg2[例:强制牙膏涨价→牙线销量] Level3 --> Q3[“如果我曾做...?”
What if I had done?] Level3 --> Op3[反事实推理
吸收→行动→预测] Level3 --> Eg3[例:没吃阿司匹林头还痛吗?] subgraph "因果图" direction LR Node(变量) --> Arrow(因果箭头) Arrow --> Surgery[图手术
删除入箭表示干预] Arrow --> CF[反事实模拟
结合事实修改模型] end Level1 -- 数据来自观察 --> Node Level2 -- 用手术模拟 --> Surgery Level3 -- 用三步法模拟 --> CF style Level1 fill:#e1f5fe style Level2 fill:#fff9c4 style Level3 fill:#ffe0b2 style 因果图 fill:#d1c4e9
4. 重要原理与公式
4.1 概率与因果的鸿沟
- 原理:不能仅用概率定义因果关系。即使
P(Y|X) > P(Y),也不能得出X是Y的原因,因为可能存在共同原因Z使得X和Y相关(混杂)。 - 珀尔的正确表述:
X是Y的原因,当且仅当P(Y | do(X)) ≠ P(Y)。这里do(X)将因果关系与关联区分开来。
4.2 do-算子的数学意义
- 定义:
do(X=x)表示在系统中强制将变量X设为值x。它等价于在因果图中删除所有指向X的箭头,并将X固定为x,然后计算其他变量的分布。 - 公式:
P(Y | do(X))代表干预后Y的概率。它与条件概率P(Y | X)一般不等。
4.3 反事实推理的三步算法
珀尔提出的通用框架:
- 吸收:利用观察证据
E更新对外生变量(未观察的误差项)的信念,得到P(U|E)。 - 行动:对模型执行
do(X=x')操作(删除指向X的箭头并设X=x'),得到修改后的模型M_x。 - 预测:在修改后的模型
M_x中,利用更新后的信念P(U|E)计算目标变量Y的值,得到P(Y_{X=x'} = y | E)。
5. 实例辅助理解
例1:猛犸象狩猎(图1.1)
- 问题:如何提高狩猎成功率?
- 因果图:包含“猎人数量”、“天气”、“地形”、“动物警觉性”等节点,箭头指向“成功”。每个因素都是原因。
- 干预层:如果我们考虑“增加猎人数量”,我们实际上是在脑中修改因果图中“猎人数量”节点,并观察“成功”的变化。这就是一个干预 (
do(猎人数量+1)) 的模拟。 - 反事实层:假设这次狩猎失败了,我们问:“如果那天天气好,我们会成功吗?”这需要结合失败的事实(吸收)和假设的干预(天气好),进行反事实推理。
例2:行刑队(图1.4 - 1.6)
这个例子系统地展示了三个层次。
- 变量:
CO(法庭命令),C(上尉信号),A(士兵A开枪),B(士兵B开枪),D(囚犯死亡)。 - 因果图:
CO → C → A,C → B,A → D,B → D。 - 关联层:观察
D=真→ 可推出A=真且B=真且C=真且CO=真。观察A=真→ 可推出B=真(因为A和B有共同原因C)。 - 干预层:问“如果我们强制士兵
A开枪 (do(A=真)),会怎样?” → 删除C→A,设A=真→ 结果D=真(因为A直接致死),但B不受影响(可能没开枪)。 - 反事实层:观察到囚犯死了,且我们知道
A开了枪。问“如果士兵A没开枪,囚犯还会死吗?” → 吸收:由死亡推知C和B都发生了;行动:设A=假;预测:B仍会开枪,所以D=真。结论:A 的不开枪不会改变结果。
例3:疫苗接种(图1.7)
- 问题:疫苗是有益还是有害?
- 数据:数据显示,因接种疫苗而死的人数(99人)多于因患病而死的人数(40人)。若只看关联,会错误地认为疫苗有害。
- 反事实层:问“如果不接种疫苗,会怎样?”(
do(接种率=0))。通过模型计算,反事实世界中将有4000人死于疾病,而真实世界只有139人死于疫苗或疾病。因此疫苗有益。 - 核心:反事实推理纠正了关联带来的错误印象,揭示了真实的因果效应。
6. 与前后的联系
- 与引言的联系:引言提出了因果推断引擎的蓝图,而本章正是对这一蓝图的具体展开。因果之梯的三个层次正是引擎需要处理的三类查询。因果图则是引擎中“因果模型”的主要形式。
- 与后续章节的联系:
- 第2章将回顾统计学如何回避因果,以及休厄尔·赖特如何通过路径图(因果图的前身)开创因果推断的先河。
- 第3章介绍贝叶斯网络,它与因果图有紧密的数学联系,但缺乏因果方向。理解本章有助于理解第3章的局限。
- 第4章及以后将详细介绍如何利用因果图来识别和消除混杂(后门准则)、如何从观察数据中估计干预效应(
do-演算)、如何进行中介分析等。这些都是攀登因果之梯的具体方法。
7. 总结与重点
核心要点
- 因果之梯的三个层次:关联、干预、反事实。每一层都建立在前一层之上,并释放出新的认知能力。
- 因果图是因果推理的基础工具:它以直观的方式编码因果假设,并通过图手术来模拟干预和反事实。
do-算子:是区分观察与干预的关键符号,是因果语言的核心。- 反事实推理的三步法:吸收、行动、预测,为算法化反事实提供了清晰路径。
- 概率不能定义因果,但因果模型可以告诉我们如何从概率数据中提取因果信息。
常见难点
- 混淆关联与干预:容易把
P(Y|X)当作P(Y|do(X))。需要牢记do操作意味着主动改变世界,而观察只是被动看世界。 - 理解图手术:为什么删除指向干预变量的箭头?因为干预切断了变量与它原有原因的联系,使其只受干预者的控制。
- 吸收步骤的直觉:反事实推理中的“吸收”看似神秘,实际上是在利用观察数据对模型中的不确定性(如误差项)进行后验更新。在确定性模型中(如行刑队),吸收就是逻辑推断。
学习建议
- 画图练习:对每个因果问题,尝试画出因果图。用箭头明确谁“听命”于谁。
- 动手做图手术:遇到干预或反事实问题时,在草图上划掉箭头,然后重新推理结果。这有助于内化
do操作的含义。 - 区分三个层次:对同一个问题,尝试从三个层次分别提问,并思考答案有何不同。例如,针对“咖啡与头痛”:
- 关联:喝咖啡的人头痛的概率?
- 干预:强制所有人喝咖啡,头痛的概率?
- 反事实:某人喝了咖啡后头痛,如果他不喝,头还会痛吗?
- 与引言呼应:将因果之梯的层次与引言中的因果推断引擎对应起来。关联对应数据输入,干预对应查询中的
do,反事实对应更复杂的查询。
本章是全书的核心,深刻理解因果之梯的三个层次以及因果图的手术机制,将为后续学习打下坚实的基础。
《The Book of Why》第2章“From Buccaneers to Guinea Pigs: The Genesis of Causal Inference”深度讲解
引言:因果思想的暗黑时代
第2章是一段引人入胜的科学史,讲述了统计学的诞生与因果推断的分离。正如海盗(buccaneers)一样,早期的统计学家如高尔顿和皮尔逊在探索数据的海洋时,无意中丢弃了因果这个珍贵的货物,而转向了纯粹的关联分析。本章的主人公休厄尔·赖特(Sewall Wright)则像一位孤独的灯塔守护者,试图将因果的火种保留下来。理解这段历史,能帮助我们深刻体会为何因果推断在长达半个多世纪里被科学界排斥,以及它是如何艰难地破土而出的。
1. 基础概念:从优生学到相关
1.1 弗朗西斯·高尔顿 (Francis Galton) 与优生学
高尔顿是查尔斯·达尔文的表弟,一位博学的维多利亚时代科学家。他痴迷于证明“天才”是遗传的,因此研究了大量家族数据。在这个过程中,他遇到了一个关键问题:子代的特征(如身高)似乎并不完全复制父代,而是趋向于平均值。
1.1.1 关键概念:回归均值 (Regression to the Mean)
- 定义:一个变量在第二次测量时,如果第一次测量值偏离平均水平,那么第二次测量值有向总体均值靠近的趋势。
- 例子:
- 身材非常高的父亲,其儿子的平均身高虽然也高于平均,但通常比父亲矮一些。
- 第一次考试得分极高的学生,第二次考试往往分数会有所下降。
- 高尔顿的误解:最初,高尔顿认为回归均值是一种需要生物学解释的物理力,类似于弹簧将身高拉回中心。为此,他设计了著名的高尔顿板 (Galton board) 来模拟遗传过程。
1.1.2 高尔顿板与遗传模型
- 高尔顿板:一个钉板阵,小球从上落下,随机左右弹跳,最终堆积成正态分布(钟形曲线)。这模拟了随机变异的累积。
- 两代模型:高尔顿将两个高尔顿板串联,发现第二代的分布会变得更宽(变异增大)。但现实中人类身高的分布却保持稳定。为了解释这种稳定性,他在两个板之间加入了斜槽 (chutes),将偏离中心的小球拉回中心。他以为这就是回归均值的机制。
1.1.3 从回归到相关
- 转折点:高尔顿后来发现,不仅父代身高可以预测子代,子代身高也可以“预测”父代(虽然方向相反)。这让他意识到,回归不是单向的因果力,而是一种对称的关系。于是他发明了相关 (correlation) 的概念,用相关系数来衡量这种对称的关联强度。
- 散点图与椭圆:高尔顿在绘制父子身高的散点图时,发现数据点形成一个椭圆。椭圆的长轴(主对角线)并不等于回归线,回归线是连接椭圆左右两侧切点的线(见图2.2, 2.3)。这揭示了回归与相关的数学本质。
1.2 卡尔·皮尔逊 (Karl Pearson) 与相关性系数的诞生
皮尔逊是高尔顿的狂热追随者,他将高尔顿的想法数学化,并成为现代统计学的奠基人之一。
1.2.1 关键概念:皮尔逊相关系数 (Pearson Correlation Coefficient)
- 符号:通常用 $ r $ 表示。
- 公式:$$ r_{XY} = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y} $$,度量两个变量线性相关程度,取值范围 [-1, 1]。
- 意义:相关是完全对称的,它只告诉我们两个变量一起变化的趋势,不涉及任何方向性(因果方向)。
1.2.2 皮尔逊的因果观:抛弃因果
- 实证主义:皮尔逊深受当时实证主义哲学影响,认为科学只能描述观察到的规律,不能谈论不可观察的“原因”。他认为因果只是完美相关的一种特例($ r = \pm 1 $)。
- 名言:“相关就是比因果更宽泛的范畴,因果只是相关的极限。”
- 后果:在皮尔逊的领导下,统计学变成了一门专注于数据约减 (reduction of data) 的学科,因果语言被彻底清除。他强调客观性,认为任何主观假设(如因果方向)都应被排除。
1.2.3 皮尔逊与“虚假相关”
- 皮尔逊自己也发现了一些“虚假相关”的例子,例如将男性和女性头骨数据合并后,原本不相关的头骨长度和宽度变得相关了。他称之为“人工混合 (artificial mixture)”。这实际上是混杂 (confounding) 的一种表现,但他无法用因果语言解释,只能将其视为统计上的“虚假”。
- 讽刺:皮尔逊试图消除所有主观性,但“虚假相关”这个概念本身就隐含着对“真实”关联的因果判断。
2. 核心人物:休厄尔·赖特 (Sewall Wright) 与路径图的诞生
赖特是一位遗传学家,他面对的是复杂的生物系统,无法仅用相关分析来解决问题。他需要一个工具来表达和量化因果关系。
2.1 关键概念:路径图 (Path Diagram)
- 定义:一种用有向箭头连接变量的图形,箭头从原因指向结果,表示直接的因果影响。
- 特点:
- 节点:变量(可观测或不可观测)。
- 箭头:因果方向,表示一个变量“听命于”另一个变量。
- 缺失的箭头:同样重要,表示没有直接的因果影响(这是因果假设的关键)。
- 例子:图2.7展示了影响豚鼠毛色的因素,包括遗传因素($H$)、发育因素($D$)、环境因素($E$)以及父母贡献等。箭头清楚地表明了因果关系。
2.2 关键概念:路径系数 (Path Coefficient)
- 定义:附着在每个箭头上的一组数字,表示原因变量变化一个单位时,结果变量预期变化的因果效应大小(通常标准化为单位标准差)。
- 解释:路径系数 $p_{YX}$ 代表在保持其他所有变量不变的情况下,$X$ 对 $Y$ 的直接因果效应。
- 与回归系数的区别:回归系数(如 $b_{YX}$)仅仅是数据拟合的统计结果,可能包含混杂。而路径系数是模型假设下的因果参数。赖特的关键创新在于,他给出了如何将路径系数与观测到的相关系数联系起来的规则。
2.3 赖特的伟大贡献:建立从因果到相关的桥梁
- 路径追踪规则 (Path Tracing Rules):赖特证明,两个变量之间的相关系数可以分解为它们之间所有因果路径和非因果路径上的路径系数乘积之和。具体规则包括:
- 不能同时沿同一箭头来回走。
- 路径可以沿箭头方向(因果链),也可以逆向箭头(通过共同原因),但不能同时包含前向和后向箭头(除了通过协方差连接的双向箭头)。
- 核心思想:给定一个因果图,我们可以预测应该观察到什么样的相关系数模式。反过来,如果我们有相关系数的数据,并且有因果图作为假设,我们可以求解方程组来估计路径系数,从而得到因果效应的量化估计。
- 例子:豚鼠出生体重 (Guinea Pig Birth Weight)(图2.8):
- 问题:孕期每增加一天,豚鼠出生体重增加5.66克。但这是因为真的多长了一天,还是因为晚生的豚鼠往往来自更小的窝(更少竞争)?
- 路径图:包括孕期($P$)、窝大小($L$)、生长率($Q$)、出生体重($X$)。假设 $L$ 影响 $P$ 和 $Q$,$P$ 和 $Q$ 影响 $X$。
- 计算:通过路径追踪规则,将观测到的相关系数(如 $r_{PX}, r_{LX}, r_{LP}$)表示为未知路径系数的方程。求解后,赖特得出孕期每增加一天的真实因果效应是3.34克,而不是5.66克。这剔除了因窝大小造成的混杂。
2.4 赖特与统计学界的冲突
- 亨利·奈尔斯 (Henry Niles) 的批评:奈尔斯是皮尔逊的学生,他完全站在相关主义的立场,认为赖特的路径分析是“哲学的谬误”。他声称因果就是完美相关,赖特的假设是武断的,方法不可靠。
- 赖特的回应:赖特冷静地指出,路径分析不是从数据中发现因果关系,而是将已知的因果知识与数据结合,来量化我们感兴趣但不可直接观测的因果参数。他强调,没有因果假设,就无法进行因果分析。
3. 构建知识体系:因果与相关的对立与融合
(客观,摒弃因果)] end subgraph 赖特的挑战 B1[赖特:遗传学需要因果] B1 --> B2[发明:路径图] B2 --> B3[发明:路径系数] end subgraph 关键连接 C1[路径追踪规则] end subgraph 结果 D1[从因果图预测相关] D2[从相关数据估计因果效应] end B2 --> C1 B3 --> C1 C1 --> D1 C1 --> D2 A3 --> C1 D2 --> E[量化因果效应
(如出生体重例子)] style B2 fill:#f9f,stroke:#333,stroke-width:2px style B3 fill:#f9f,stroke:#333,stroke-width:2px style C1 fill:#ccf,stroke:#333
核心关系:
- 对立:皮尔逊学派认为相关是科学的终结,因果是多余的形而上学。赖特则认为,必须引入因果假设(路径图),才能从相关中提取出真正的因果信息。
- 统一:赖特的路径追踪规则实际上连接了因果世界和相关世界。它表明,在因果假设明确的前提下,相关确实可以蕴含因果信息。这是对“相关不蕴含因果”这一教条的深刻修正。
4. 实例辅助理解
实例1:高尔顿的身高数据与回归
- 问题:预测儿子的身高。
- 数据:一对父子身高数据。
- 分析:
- 如果父亲身高72英寸,儿子的平均身高约71英寸。这就是回归到均值。
- 如果画散点图,数据形成椭圆。回归线(预测儿子身高)和另一条线(预测父亲身高)不同,表明回归是对称的,不蕴含因果。
- 要点:高尔顿最初想找因果(遗传力),却发现了统计规律(相关),这标志着一个转折。
实例2:赖特的豚鼠出生体重
- 问题:孕期增加一天的真实生长速度是多少?
- 数据:观测了孕期、窝大小、出生体重。
- 路径图:假设窝大小影响孕期和生长率,孕期和生长率都影响出生体重。
- 路径分析:
- 写下观测到的相关系数(如孕期与出生体重的相关 = 5.66克/天?其实是标准化后的系数)。
- 根据路径追踪规则,将每个观测相关表示为路径系数的函数。
- 解方程得到路径系数,其中“孕期→出生体重”的系数是3.34克/天(真实因果效应)。
- 启示:原始观测相关(5.66)是混杂后的结果;路径分析剥离了混杂,得到纯净的因果效应。
5. 与前后的联系
- 与第1章的联系:
- 高尔顿和皮尔逊停留在因果之梯的第一层(关联),并试图用第一层语言解释一切。
- 赖特的路径分析是登上第二层(干预)的初步尝试,因为他明确量化了因果效应(路径系数),尽管他尚未使用
do-算子。
- 与第3章的联系:
- 贝叶斯网络与路径图有直接的数学联系(都是DAG)。区别在于,贝叶斯网络最初是为了概率计算,而路径图明确用于因果建模。
- 第3章将介绍贝叶斯网络的概率推理,而本章的路径图则提供了因果结构。
- 与第4章及以后:
- 本章的“路径追踪规则”是后来d-分离 (d-separation) 和后门准则 (back-door criterion) 的前身。
- 赖特对“直接效应”和“间接效应”的区分,为第9章的中介分析 (mediation analysis) 奠定了基础。
6. 总结与重点
核心要点
- 相关与回归的起源:高尔顿在寻找遗传因果时发现了相关和回归,但它们只是统计规律,不蕴含因果方向。
- 统计学的“去因果化”:皮尔逊将相关数学化,并基于实证主义哲学,将因果语言逐出统计学,将统计学定义为一门数据约减的科学。
- 路径图的诞生:赖特发明了路径图,这是第一个能够明确表达因果假设并量化因果效应的工具。
- 路径追踪规则:赖特建立了从因果图到相关模式的桥梁,使得我们可以利用观察数据估计因果效应(路径系数)。
- 因果推断的核心原则:没有因果假设,就没有因果答案。赖特的工作证明了,在明确假设下,相关确实可以用于推断因果。
常见难点
- 混淆路径系数与回归系数:路径系数是因果假设下的参数,回归系数是数据的统计描述。在赖特的线性模型中,路径系数可以通过回归系数间接得到,但意义完全不同。
- 理解路径追踪规则:初学者容易混淆因果路径和非因果路径。需要理解,一条路径要能传递相关性,必须满足一定的条件(例如,不能有碰撞节点 collider)。这为后续的d-分离埋下伏笔。
- 为何赖特的贡献被忽视:由于皮尔逊学派的强大影响和费歇尔(R.A. Fisher)的排斥,路径分析在长达四十年里被主流统计学忽视。
学习建议
- 画图练习:尝试自己画出简单的路径图(如X→Y,有共同原因Z),然后用路径追踪规则写出X与Y的相关系数表达式。
- 区分概念:制作一张表,对比“相关”、“回归系数”、“路径系数”的定义和用途。
- 历史视角:理解这段历史有助于认识到,因果推断的复兴不仅仅是新方法的出现,更是对科学哲学的一次深刻反思。
- 连接未来:在学习后续章节(特别是第7章“后门准则”和第9章“中介”)时,回想本章的路径图是如何处理这些问题的雏形的。
本章不仅是一段历史,更是因果推断基本思想的源头。赖特孤独的斗争,为后来者铺平了道路。
《The Book of Why》第3章“From Evidence to Causes: Reverend Bayes Meets Mr. Holmes”深度讲解
引言:从观察到原因的桥梁
第3章将我们带回18世纪,与托马斯·贝叶斯(Thomas Bayes)和虚构的侦探夏洛克·福尔摩斯(Sherlock Holmes)相遇。福尔摩斯以从证据推断原因为傲,而这正是逆概率问题的核心。本章旨在展示如何用概率语言(特别是贝叶斯法则)进行从证据到假设的推理,并引出能够处理复杂概率关系的工具——贝叶斯网络。然而,正如我们将看到的,贝叶斯网络虽然强大,但本身并不具备因果方向,这为后续引入真正的因果模型埋下了伏笔。
1. 基础概念:逆概率与贝叶斯法则
1.1 从证据到原因:逆概率问题
- 定义:给定观察到的证据(例如,窗户破碎),推断导致该证据的可能原因(例如,男孩踢球、风等)的概率。这与正向概率(给定原因,预测证据)相反。
- 例子:我们很容易预测如果鲍比向窗户扔球会发生什么(正向),但很难在窗户破碎后推断是哪个男孩扔的(逆概率)。这正是福尔摩斯的专长。
1.2 贝叶斯法则 (Bayes’ Rule)
贝叶斯法则提供了从正向概率计算逆概率的数学公式。
公式:
$$ P(H|E) = \frac{P(E|H) \times P(H)}{P(E)} $$其中:
- $ P(H) $:先验概率 (Prior Probability),在观察到证据之前对假设 $ H $ 的信念。
- $ P(E|H) $:似然 (Likelihood),在假设 $ H $ 为真的条件下观察到证据 $ E $ 的概率。
- $ P(E) $:证据概率 (Evidence Probability),观察到证据 $ E $ 的总概率(可通过全概率公式计算)。
- $ P(H|E) $:后验概率 (Posterior Probability),在观察到证据后对假设 $ H $ 的更新信念。
例子:茶和烤饼(表3.1):
- 假设:顾客点茶。
- 证据:顾客点烤饼。
- 已知:$ P(茶) = 2/3 $,$ P(烤饼|茶) = 1/2 $。
- 则:$ P(茶 \text{ 且 } 烤饼) = 1/3 $;$ P(烤饼) = 5/12 $。
- 后验:$ P(茶|烤饼) = P(茶 \text{ 且 } 烤饼) / P(烤饼) = (1/3) / (5/12) = 4/5 $。即看到顾客点烤饼后,他点茶的概率从2/3上升到4/5。
1.3 贝叶斯法则的意义
- 更新信念:它提供了一种将先验知识与新证据结合的客观方法。
- 量化不确定性:它将信念表达为概率,使推理可以量化。
- 哲学争议:先验概率的引入曾受到频繁主义者(frequentists)的批评,因为它似乎引入了主观性。但贝叶斯学派认为,正是这种主观性使我们能够利用背景知识。
2. 贝叶斯法则的应用实例:医学测试
- 背景:40岁女性进行乳腺癌筛查,结果呈阳性。她有多大概率真的患有癌症?
- 数据(基于BCSC):
- 先验:$ P(癌症) = 1/700 $。
- 灵敏度(似然):$ P(阳性|癌症) = 73\% $。
- 假阳性率:$ P(阳性|无癌症) = 12\% $。
- 计算:
- 证据概率 $ P(阳性) = P(阳性|癌症) \times P(癌症) + P(阳性|无癌症) \times P(无癌症) = 0.73 \times (1/700) + 0.12 \times (699/700) \approx 0.121 $。
- 后验 $ P(癌症|阳性) = \frac{0.73 \times 1/700}{0.121} \approx 1/116 $。
- 启示:尽管测试呈阳性,患癌概率仍低于1%。这令人惊讶,因为人们常混淆灵敏度($ P(阳性|癌症) $)与后验概率($ P(癌症|阳性) $)。贝叶斯法则清晰地纠正了这一误解。
3. 从贝叶斯法则到贝叶斯网络
当变量增多,关系复杂时,直接应用贝叶斯法则会变得计算困难。这时需要一种结构化表示——贝叶斯网络。
3.1 贝叶斯网络的定义
- 定义:一个有向无环图 (DAG, Directed Acyclic Graph),其中:
- 节点:代表随机变量。
- 有向边:表示变量之间的概率依赖关系(父节点指向子节点)。
- 条件概率表 (CPT, Conditional Probability Table):每个节点附有一个CPT,量化了在给定父节点取值时该节点的概率分布。
- 核心性质:给定其父节点,每个节点条件独立于其非后代节点。这称为局部马尔可夫性 (Local Markov Property)。
3.2 三种基本连接模式 (Junctions)
理解贝叶斯网络中信息如何流动的关键是识别三种基本结构。这些结构在因果推断中至关重要。
3.2.1 链 (Chain): $ A \rightarrow B \rightarrow C $
- 信息流动:$ A $ 和 $ C $ 通常相关(通过 $ B $)。
- 条件独立:当控制 $ B $(即已知 $ B $ 的值)时,$ A $ 和 $ C $ 变得独立。信息被 $ B $ “屏蔽”了。
- 例子:火 ($A$) → 烟 ($B$) → 警报 ($C$)。知道有烟时,火的存在与否不再影响警报的概率(假设烟是唯一途径)。
3.2.2 叉 (Fork): $ A \leftarrow B \rightarrow C $
- 信息流动:$ A $ 和 $ C $ 通常相关,因为存在共同原因 $ B $。
- 条件独立:当控制 $ B $ 时,$ A $ 和 $ C $ 变得独立。
- 例子:鞋码 ($A$) ← 年龄 ($B$) → 阅读能力 ($C$)。控制年龄后,鞋码与阅读能力不再相关。
3.2.3 对撞子 (Collider): $ A \rightarrow B \leftarrow C $
- 信息流动:$ A $ 和 $ C $ 通常是独立的(没有路径连接它们)。
- 条件依赖:当控制 $ B $ 时,$ A $ 和 $ C $ 反而变得相关(产生非因果的虚假相关)。这称为“解释-消失效应 (explain-away effect)”。
- 例子:天赋 ($A$) → 成名 ($B$) ← 美貌 ($C$)。在普通人中,天赋和美貌独立。但在成名的人中,如果一个人天赋平平,则他更可能因为美貌而成功,从而天赋和美貌在名人群体中出现负相关。
3.3 贝叶斯网络中的推理
贝叶斯网络支持双向推理:既可以自顶向下(从原因到证据),也可以自底向上(从证据到原因)。这通过信念传播 (belief propagation) 算法实现,该算法在节点间传递消息以更新后验概率。
- 例子:丢失的行李(图3.5, 3.6):
- 变量:
BagOnPlane(行李在飞机上)、TimeElapsed(时间流逝)、BagOnCarousel(行李在传送带上)。 - 关系:如果行李在飞机上,那么它随着时间推移更可能出现在传送带上;如果不在飞机上,则永远不可能出现。
- 推理:随着时间流逝而没有看到行李,信念传播会动态更新
BagOnPlane的后验概率,形成一条“放弃希望的曲线”。这展示了贝叶斯网络如何实时处理不确定性。
- 变量:
4. 贝叶斯网络的应用
4.1 DNA识别(Bonaparte软件)
- 问题:灾难后通过亲属DNA识别遇难者身份。
- 方法:将家谱图转化为贝叶斯网络,节点代表个体的基因型(可观测)和等位基因(不可观测)。通过信念传播,利用多个亲属的DNA信息推断遇难者的最可能基因型,从而识别身份。
- 优势:能够整合来自远亲的信息,具有透明性(可解释每一步推理)。
4.2 手机纠错码(Turbo Codes)
- 问题:无线通信中信号受噪声干扰,需要高效纠错。
- 方法:将编码过程建模为贝叶斯网络,接收端使用信念传播(迭代解码)来恢复原始信息。Turbo码及其变体(如LDPC码)是现代通信(3G/4G/5G)的基础。
- 关键:信念传播在两个并行解码器之间交换信息,逐步收敛到正确结果。
5. 从贝叶斯网络到因果图:本章的桥梁作用
本章最后一部分至关重要,它区分了概率性贝叶斯网络和因果贝叶斯网络(即因果图)。
- 相同点:两者都是DAG,都编码了变量间的依赖关系。
- 关键区别:
- 贝叶斯网络:箭头仅表示概率依赖(“给定父节点,子节点与祖先独立”)。它没有因果方向的含义,不能区分 $ A \rightarrow B $ 和 $ A \leftarrow B $ 如果它们蕴含相同的条件独立性。它只能处理“观察”层面的查询(第一层)。
- 因果图:箭头明确表示因果方向(“$ Y $ 倾听 $ X $”)。它能够回答干预和反事实问题(第二、三层)。因果图是贝叶斯网络加上因果解释。
- 构建方式:
- 贝叶斯网络:从概率依赖出发,可能由数据学习得出。
- 因果图:从因果知识出发,基于“谁导致谁”的科学理解。
- 推理能力:
- 贝叶斯网络:可以计算 $ P(Y|X) $。
- 因果图:可以计算 $ P(Y|do(X)) $ 和反事实概率。
核心思想:贝叶斯网络提供了处理不确定性和复杂依赖的框架,而因果图则为这个框架注入了方向性,使其能够攀登因果之梯。
6. 概念关系图
(概率依赖DAG)] end subgraph 因果世界 F[因果知识
(谁导致谁)] --> G[因果图
(因果DAG)] G --> H[干预与反事实推理
(do-算子,图手术)] end subgraph 本章桥梁 E -- 箭头本身无因果意义 --> G E -- 提供概率计算基础 --> G G -- 因果解释赋予方向 --> H end subgraph 三种基本连接 I[链 A→B→C] --> J[信息在B处被屏蔽] K[叉 A←B→C] --> J L[对撞子 A→B←C] --> M[信息在B处被开启
(条件依赖)] end E --> I E --> K E --> L style G fill:#f9f,stroke:#333,stroke-width:2px style E fill:#ccf,stroke:#333
7. 与前后的联系
- 与第1章的联系:
- 第1章提出了因果之梯的三个层次。本章的贝叶斯网络主要工作在第一层(关联),即通过观察更新信念。但因果图的引入将我们带到第二层和第三层。
- 第1章中的行刑队例子展示了干预和反事实,而本章的贝叶斯网络(如行李丢失)仅处理了观察性推理。
- 与第2章的联系:
- 第2章的高尔顿、皮尔逊和赖特的工作奠定了相关和因果图的基础。贝叶斯网络可以看作是概率图模型,而赖特的路径图是因果图的前身。两者在数学上是同构的,但解释不同。
- 与后续章节的联系:
- 第4章将详细讨论混杂(叉结构)以及如何通过“后门准则”消除混杂,这正是利用因果图进行干预估计的第一步。
- 第6章中的悖论(如辛普森悖论、伯克森悖论)与本章的三种连接直接相关。理解对撞子对于理解选择性偏差至关重要。
- 第7-9章将深入探讨如何利用因果图进行干预、反事实和中介分析,这些都建立在贝叶斯网络的概率计算基础之上,但需要因果方向。
8. 总结与重点
核心要点
- 贝叶斯法则:提供了从证据(效果)更新假设(原因)信念的数学工具,是逆概率推理的基础。
- 贝叶斯网络:用DAG和CPT表示复杂概率依赖,支持高效的信念传播和证据推理。
- 三种基本连接:链、叉、对撞子揭示了信息在网络中如何流动,以及条件独立/依赖的条件。它们是理解统计关联与因果关系的钥匙。
- 对撞子的重要性:控制对撞子会引入虚假相关(解释-消失效应),这是许多统计悖论(如伯克森悖论)和选择性偏差的根源。
- 贝叶斯网络 ≠ 因果图:贝叶斯网络只表示概率依赖,不能区分因果方向;因果图需要额外注入因果知识,才能处理干预和反事实。
常见难点
- 混淆条件概率与干预:贝叶斯网络计算的 $ P(Y|X) $ 是条件概率,而因果图的目标是 $ P(Y|do(X)) $。初学者容易混淆。
- 理解对撞子的反直觉性:为何控制一个共同效应会导致原因之间出现相关?这需要反复用例子(如天赋与美貌)来内化。
- 区分三种结构:需要大量练习,通过给定图判断变量间的条件独立关系。
学习建议
- 动手计算:自己推导医学测试例子中的贝叶斯公式,加深对先验、似然、后验的理解。
- 画图练习:对每种连接,画出图并思考在不同条件(控制某个节点或不控制)下,其他节点间的独立性。
- 从例子中学习:重读行李丢失和DNA识别的例子,思考信念传播是如何利用网络结构进行推理的。
- 记住关键区别:制作一张表格对比贝叶斯网络和因果图,明确它们在箭头含义、查询类型、计算目标上的不同。
- 为下一章铺垫:特别注意叉结构(混杂)和对撞子结构(选择偏差),因为它们将是第4章的核心。
本章是概率与因果之间的桥梁。掌握了贝叶斯网络及其三种基本连接,你就拥有了理解后续因果分析所有核心概念的钥匙。
《The Book of Why》第4章“Confounding and Deconfounding: Or, Slaying the Lurking Variable”深度讲解
引言:混杂——因果推断的头号敌人
第4章从一个古老的故事开始:但以理(Daniel)在巴比伦王宫拒绝食用国王的酒肉,请求只吃素菜喝水。他担心负责的太监因自己的决定而掉脑袋,于是提议做一个为期十天的对照实验:他和三个朋友只吃素,其他少年吃国王的膳食,十天后比较他们的面貌。这个实验具备了现代随机对照试验的雏形:设置对照组、前瞻性、以及比较的思想。但但以理没有意识到混杂的存在——如果他和朋友原本就比其他人更健康,那么实验结果的差异可能不是饮食造成的,而是初始差异造成的。
本章的核心就是混杂以及如何消除混杂(去混杂)。我们将学习如何用因果图识别混杂,并掌握一种强大的去混杂工具——后门准则,它使我们能够在观察研究中估计因果效应,而不必总是依赖随机对照试验。
1. 基础概念
1.1 混杂 (Confounding) 与混杂因子 (Confounder)
- 定义:混杂是指当我们试图评估某个变量 $X$ 对 $Y$ 的因果效应时,存在一个第三变量 $Z$,它同时影响 $X$ 和 $Y$,导致 $X$ 和 $Y$ 之间出现非因果的虚假关联。
- 混杂因子:这个第三方变量 $Z$ 被称为混杂因子。它必须满足:
- 它与 $X$ 有关联(通常它是 $X$ 的原因)。
- 它直接影响 $Y$(它是 $Y$ 的原因)。
- 它不在 $X$ 到 $Y$ 的因果路径上(即它不是中介)。
- 因果图表示:混杂结构表现为一个叉 (fork):$X \leftarrow Z \rightarrow Y$。
- 例子:在研究步行与死亡率的关系时(图4.2),年龄 ($Z$) 既影响一个人是否选择步行 ($X$),又直接影响死亡率 ($Y$)。因此年龄是一个混杂因子。
1.2 随机对照试验 (Randomized Controlled Trial, RCT)
- 定义:通过随机化分配将研究对象分为处理组(给予干预)和对照组(不给予干预),从而在两组之间创造可比性的实验方法。
- 目的:随机化切断了处理变量 $X$ 与所有潜在混杂因子 $Z$ 之间的联系(即删除了图中指向 $X$ 的所有箭头,如图4.6),使得 $X$ 仅与一个随机数有关,从而保证 $P(Y|do(X)) = P(Y|X)$。
- 费舍尔的贡献:R. A. 费舍尔(Fisher)将随机化引入实验设计,指出随机化能防止“大自然”混淆处理效果。正如他的女儿所言,随机化是“对大自然的巧妙审讯”。
- 局限性:RCT有时不可行(如研究吸烟对肺癌的影响)、不道德(强制人吸烟)或昂贵。
1.3 交换性 (Exchangeability)
- 定义:如果处理组和对照组在没有处理的情况下,其结果(潜在结果)的分布相同,则称两组是可交换的。也就是说,如果我们可以交换两组人的标签,而不会改变未处理的结果,那么处理组和对照组就是可交换的。
- 用潜在结果表达:对于每个个体,存在两个潜在结果 $Y_{x=1}$(如果接受处理)和 $Y_{x=0}$(如果未接受处理)。如果处理组和对照组的 $Y_{x=0}$ 分布相同,则它们对于未处理结果是可交换的。对于处理结果亦然。
- RCT与交换性:随机化保证了处理组和对照组在所有与结果相关的因素(包括未测量的)上都是可交换的。因此,RCT是达到交换性的金标准。
2. 核心知识点
2.1 混杂的因果定义
在没有 $do$-算子的时代,混杂的定义混乱不清。珀尔提出,混杂应该直接用干预来定义:
$$ \text{存在混杂} \iff P(Y|X) \neq P(Y|do(X)) $$也就是说,如果我们观察到的条件概率 $P(Y|X)$ 与通过干预得到的概率 $P(Y|do(X))$ 不同,那么观察到的关联中包含了混杂偏差。
这个定义将混杂问题明确地定位在因果之梯的第二层(干预)与第一层(观察)的差异上,从而为寻找去混杂方法提供了清晰的目标。
2.2 经典流行病学定义的缺陷
经典的混杂定义通常包括三条:
- $Z$ 与 $X$ 相关(在总体中)。
- $Z$ 与 $Y$ 相关(在未处理者中)。
- $Z$ 不在 $X$ 到 $Y$ 的因果路径上。
然而,这种定义有严重缺陷:
- 它不能处理中介:如果 $Z$ 是中介($X \rightarrow Z \rightarrow Y$),则满足1和2,但控制 $Z$ 会阻断因果效应。
- 它不能处理对撞子:如果 $Z$ 是对撞子($X \rightarrow Z \leftarrow Y$),则控制 $Z$ 会引入虚假相关。
- 例子:图4.4中,控制一个变量的“代理”也可能导致偏差。
2.3 后门准则 (Back-door Criterion) —— 识别去混杂变量的利器
后门准则是珀尔提出的一个图形准则,用于判断一个变量集合 $Z$ 是否足以消除 $X$ 对 $Y$ 的混杂。
定义:在一个有向无环图(DAG)中,一组变量 $Z$ 满足后门准则,当且仅当:
- $Z$ 中不包含 $X$ 的后代(即 $Z$ 中的变量不能是 $X$ 的效应)。
- $Z$ 阻断了所有从 $X$ 到 $Y$ 的后门路径。
- 后门路径:任何从 $X$ 出发,沿着箭头指向 $X$(即箭头朝向 $X$)开始,然后可以朝任意方向行进,最终到达 $Y$ 的路径。这些路径代表了可能带来混杂的非因果通道。
直观理解:后门路径是那些可能使 $X$ 和 $Y$ 产生非因果相关的路径,因为它们有指向 $X$ 的箭头。要消除混杂,我们需要阻断所有这些路径。
阻断路径的规则(重温第3章):
- 链 $A \rightarrow B \rightarrow C$:控制 $B$ 可阻断。
- 叉 $A \leftarrow B \rightarrow C$:控制 $B$ 可阻断。
- 对撞子 $A \rightarrow B \leftarrow C$:不控制 $B$ 时路径是阻断的;控制 $B$ 反而会打开路径。因此,如果后门路径中包含对撞子,且我们不控制它,则路径自然阻断,不需要处理。
调整公式 (Adjustment Formula): 如果 $Z$ 满足后门准则,则 $X$ 对 $Y$ 的因果效应可以表示为:
$$ P(Y|do(X)) = \sum_{z} P(Y|X, Z=z) P(Z=z) $$即:对每个 $Z$ 的取值(层),计算在层内观察到的 $Y$ 对 $X$ 的条件概率,然后按 $Z$ 在总人口中的分布进行加权平均。这个公式正是我们在第1章见过的可计算估计量的一个例子。
2.4 后门准则的应用:游戏中的去混杂
本章通过几个“游戏”展示了如何应用后门准则。
- 游戏1:$X$ 没有入箭 → 没有后门路径 → 无需控制。
- 游戏2:有一条后门路径 $X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$。路径中有对撞子 $B$,因此自然阻断,无需控制。
- 游戏3:后门路径 $X \leftarrow B \rightarrow Y$,必须控制 $B$ 才能阻断。
- 游戏4 (M-bias):后门路径 $X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$,自然阻断。但若错误地控制 $B$,则会打开这条路径,引入偏差。因此 $B$ 不是混杂因子,反而是偏差制造者。
- 游戏5:类似游戏4,但多了一条直接路径,需要更复杂的控制集。
这些游戏说明,判断一个变量是否应该纳入调整,不能仅凭它与 $X$ 和 $Y$ 的相关性,而必须依据因果图的结构。
2.5 随机对照试验与后门准则的关系
RCT 通过随机化,切断了所有指向 $X$ 的箭头(包括已知和未知的混杂因子)。在因果图中,这相当于删除了所有指向 $X$ 的边(图4.6)。此时,不再有任何后门路径存在,因此 $P(Y|do(X)) = P(Y|X)$。调整公式简化为直接比较两组结果。
因此,RCT 是一种通用的去混杂方法,它不需要我们事先识别具体的混杂因子。而后门准则则是一种在观察研究中利用已知测量变量来模拟 RCT 的方法。
3. 概念关系图
且不在 X→Y 因果路径上] end subgraph 解决方案 D[随机对照试验 RCT] --> E[随机化切断了所有指向 X 的箭头] D --> F[无需识别具体混杂因子] G[后门准则] --> H[识别一组变量 Z 满足:
1. Z 不含 X 的后代
2. Z 阻断所有后门路径] H --> I["调整公式:P(Y|do(X)) = ∑ P(Y|X,Z)P(Z)"] G --> J[需要明确因果图假设] end subgraph 图形基础 K[后门路径:从 X 出发,
箭头指向 X 的路径] L[阻断规则:
控制链或叉中的中间节点
不控制对撞子] end subgraph 应用与误区 M[M-bias:控制对撞子引入偏差] N[经典流行病学定义的缺陷] end A --> G A --> D K --> H L --> H H --> M H --> N
4. 实例辅助理解
实例1:步行与死亡率(Honolulu Heart Program)
- 问题:步行是否降低老年人死亡率?
- 观察数据:每日步行少于1英里的男性死亡率43%,多于2英里的死亡率21.5%。
- 可能混杂因子:年龄、健康状况、饮酒、饮食等。图4.2中,年龄作为共同原因同时影响步行和死亡,是典型的混杂因子。
- 调整:研究者调整了年龄后,差异仍然显著(41% vs 24%)。但最终结论仍保守地说“不能断定干预的效果”。
- 启示:在观察研究中,只要我们有足够好的后门变量(如年龄)并正确调整,就能获得因果估计的近似值。
实例2:M-bias(游戏4)
- 图:$X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$,无 $X \rightarrow Y$ 边。
- 直觉:变量 $B$ 与 $X$ 和 $Y$ 都相关(通过 $A$ 和 $C$),似乎符合传统混杂定义。
- 后门准则分析:唯一的后门路径 $X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$ 中包含对撞子 $B$,因此自然阻断。无需控制任何变量。
- 错误做法:若控制 $B$,则会打开后门路径,使 $X$ 和 $Y$ 出现虚假相关。因此 $B$ 不应被纳入调整。
- 现实例子:$X$=吸烟,$Y$=肺癌,$A$=社会规范,$C$=健康意识,$B$=系安全带。如果只控制 $B$(安全带使用),会引入偏差。
实例3:吸烟与流产(Weinberg 1993)
- 图4.7(游戏2变形):母亲当前吸烟 ($X$)、前一次妊娠吸烟 ($A$)、既往流产 ($C$)、未观测的异常 ($B,E$) 等。
- 问题:控制既往流产 ($C$) 是否合适?
- 分析:如果 $C$ 是 $X$ 的效应(通过未观测异常),则控制 $C$ 会阻断部分因果效应,导致估计偏倚。必须结合其他变量(如 $A$)才能正确调整。
- 结论:后门准则可以明确告诉我们哪些变量应该控制,哪些不应该。
5. 与前后的联系
- 与第1章的联系:第1章提出了因果之梯和干预的概念。混杂正是导致观察 ($P(Y|X)$) 与干预 ($P(Y|do(X))$) 不同的主要原因。第4章给出了处理混杂的具体方法——后门准则,使我们能够用观察数据估计干预效果。
- 与第3章的联系:后门准则依赖于第3章介绍的三种连接(链、叉、对撞子)以及如何阻断路径。特别是对撞子,在M-bias中至关重要。
- 与第5章的联系:吸烟与肺癌的辩论是混杂问题的经典案例。第5章将详细讲述费舍尔提出的“吸烟基因”假说,以及如何用后门准则的思想(如科恩菲尔德不等式)来反驳它。
- 与第7章的联系:后门准则是估计干预效应的一种方法。第7章将介绍更强大的后门调整公式以及前门准则、工具变量等,它们都是后门准则的扩展。
- 与第6章的联系:辛普森悖论、伯克森悖论等本质上都是混杂或选择偏差造成的,可以用后门准则分析。
6. 总结与重点
核心要点
- 混杂的定义:混杂是导致 $P(Y|X)$ 与 $P(Y|do(X))$ 不同的因素,通常由共同原因(叉结构)引起。
- 后门准则:提供了一个基于因果图的系统方法,用于识别哪些变量需要调整以消除混杂。它要求变量集 $Z$ 不含 $X$ 的后代,并阻断所有后门路径。
- 调整公式:当 $Z$ 满足后门准则时,可用 $\sum_z P(Y|X,Z)P(Z)$ 估计因果效应。
- RCT与后门准则:RCT 通过随机化自动实现后门准则的效果,而观察研究需要测量并调整合适的变量。
- 不要盲目控制:控制变量可能引入新的偏差(如控制对撞子),必须基于因果图而非简单相关性。
- 交换性:潜在结果框架中的交换性概念,与后门准则等价。
常见难点
- 混淆后门路径与因果路径:后门路径是从 $X$ 出发、箭头指向 $X$ 的路径,它们代表非因果关联。因果路径是从 $X$ 出发、箭头指向 $Y$ 的路径。
- 对撞子何时阻断何时打开:不控制对撞子时它阻断路径;控制对撞子(或其后代)时它打开路径。这是初学者最易混淆的点。
- M-bias 的反直觉性:为什么一个与 $X$ 和 $Y$ 都相关的变量不能控制?因为它位于对撞子上,控制它会引入虚假相关。
- “前处理变量”不是安全港:许多统计教科书建议控制所有“处理前”的变量,但 M-bias 表明,即使变量发生在处理前,也可能因对撞子结构而不宜控制。
学习建议
- 多画图:面对任何因果问题,先画出因果图,明确变量的关系。然后手工列出所有后门路径。
- 练习阻断路径:对每个后门路径,思考如何阻断它(控制某变量或利用对撞子自然阻断)。然后确定最小调整集。
- 重复游戏:重新做一遍本章的“游戏1-5”,用后门准则分析每个游戏的正确答案。
- 结合实际例子:回顾步行研究、M-bias 例子,思考如果让你设计一项观察研究来估计因果效应,你会测量哪些变量?
- 阅读历史:了解经典流行病学定义的缺陷,有助于理解后门准则的优越性。
第4章为我们提供了一把锋利的“后门”剑,用于斩杀混杂这个隐藏的敌人。掌握后门准则,就掌握了从观察数据中提取因果信息的核心技能。
《The Book of Why》第5章“The Smoke-Filled Debate: Clearing the Air”深度讲解
引言:一场改变公共卫生的辩论
第5章聚焦于20世纪中叶关于吸烟是否导致肺癌的激烈辩论。这场辩论不仅是科学史上的重要篇章,更是因果推断发展的关键案例。当时,随机对照试验(RCT)不可行、不道德,科学家们必须依靠观察性研究回答因果问题。本章展示了在没有随机化的情况下,如何通过多种证据、逻辑推理和初步的数学工具,最终确立吸烟与肺癌的因果关系。同时,本章也揭示了统计学界对因果推断的抵制(以R.A.费舍尔为代表),以及这种抵制如何阻碍了科学共识的形成。
1. 基础概念:研究设计与证据类型
1.1 病例对照研究 (Case-Control Study)
- 定义:追溯性研究,选择一组已患病者(病例)和一组未患病者(对照),回顾他们过去的暴露情况(如是否吸烟)。
- 优势:适用于罕见疾病,效率高。
- 局限性:易受回忆偏差、选择偏差影响;只能估计比值比(odds ratio),不能直接计算发病率。
- 例子:多尔和希尔(Doll & Hill, 1950)的研究:采访649名肺癌患者和相同数量的对照,发现肺癌患者中吸烟者比例显著高于对照。
1.2 队列研究 (Cohort Study)
- 定义:前瞻性研究,根据暴露情况分组(如吸烟者 vs 非吸烟者),追踪一段时间,比较结局(如肺癌发病率)。
- 优势:可直接计算发病率,暴露信息更可靠,可减少选择偏差。
- 局限性:耗时、昂贵,不适合罕见疾病。
- 例子:多尔和希尔的医生研究(1951年起):对英国医生发放问卷,追踪吸烟习惯与死亡率,发现吸烟者肺癌死亡率远高于非吸烟者。
1.3 剂量反应关系 (Dose-Response Relationship)
- 定义:随着暴露水平(如吸烟量)的增加,结局风险也相应增加。这是支持因果关系的重要证据之一。
- 例子:在队列研究中,每日吸烟量越大,肺癌死亡率越高。
2. 核心人物与观点:费舍尔的挑战与科恩菲尔德的反击
2.1 R.A. 费舍尔的“吸烟基因”假说
费舍尔是统计学界的巨擘,但他强烈反对吸烟导致肺癌的结论。他提出一个替代解释:存在一个共同的混杂因子——吸烟基因(constitutional hypothesis)。该基因既导致人吸烟,也使人更容易患肺癌。换句话说,吸烟和肺癌之间的关联可能是由这个未观测的基因引起的,而不是因果。
因果图表示:
吸烟基因 (U) → 吸烟 (X) ↓ 肺癌 (Y)这是一个叉结构 (fork):U 同时影响 X 和 Y,导致 X 和 Y 出现虚假相关。
逻辑后果:如果这个基因存在,那么即使吸烟本身不致癌,我们也会观察到吸烟者肺癌风险更高。因此,要证明吸烟导致肺癌,必须排除这种混杂的可能性。
2.2 科恩菲尔德不等式 (Cornfield’s Inequality)
杰罗姆·科恩菲尔德(Jerome Cornfield)提出了一个巧妙的数学反驳,针对费舍尔的假说。
核心思想:如果存在一个未测量的混杂因子 $U$ 完全解释了吸烟与肺癌之间的关联,那么 $U$ 在吸烟者中的相对频率必须非常高,并且 $U$ 本身必须是肺癌的强危险因素。
推导: 设 $RR_{XY}$ 为吸烟者相对于非吸烟者的肺癌相对风险(例如,9倍)。 设 $RR_{UY}$ 为 $U$ 相对于无 $U$ 者的肺癌相对风险。 设 $P(U|吸烟)$ 和 $P(U|非吸烟)$ 分别为 $U$ 在吸烟者和非吸烟者中的流行率。 科恩菲尔德证明,要完全解释 $RR_{XY}$,必须有:
$$ \frac{P(U|吸烟)}{P(U|非吸烟)} > RR_{XY} $$且 $RR_{UY} > RR_{XY}$ 是必要的。
数值例子:假设吸烟者肺癌风险是非吸烟者的9倍。那么吸烟基因在吸烟者中的流行率必须至少是非吸烟者的9倍。如果非吸烟者中基因流行率为11%,则吸烟者中必须达到99%。如此高的差异在生物学上极不可能。如果非吸烟者中基因流行率更高(如12%),则不等式无法满足,证明基因假说无法解释全部关联。
意义:科恩菲尔德不等式是敏感性分析的早期形式。它表明,即使存在未测量混杂,我们也可以量化需要多强的混杂才能推翻观测关联。这为在观察研究中论证因果性提供了有力工具。
3. 其他证据类型与共识形成
3.1 生物合理性 (Biological Plausibility)
- 实验室研究发现烟草焦油可导致大鼠皮肤癌,香烟烟雾中含有苯并芘等已知致癌物。这些证据增强了吸烟致癌的生物学可信度。
3.2 一致性 (Consistency)
- 不同国家、不同人群的病例对照研究和队列研究都得出一致结论,这种可重复性增加了因果关系的可信度。
3.3 时间顺序 (Temporality)
- 吸烟在前,肺癌在后,这是因果关系的必要条件。队列研究明确证实了这一点。
3.4 停止吸烟降低风险
- 戒烟者的肺癌风险随戒烟时间下降,进一步支持因果解释。
4. 希尔标准 (Hill’s Criteria)
1965年,奥斯汀·布拉德福德·希尔(Austin Bradford Hill)提出了一套评估因果关系的“观点”(viewpoints),后来被称为希尔标准,共九条:
- 强度 (Strength):关联的强度(如相对风险大小)。
- 一致性 (Consistency):不同研究、人群、条件下得到相似结果。
- 特异性 (Specificity):暴露与特定结局的关联是否唯一(有争议)。
- 时间性 (Temporality):因在前,果在后。
- 剂量反应关系 (Biological gradient):暴露水平与风险呈单调关系。
- 合理性 (Plausibility):符合现有的生物学知识。
- 连贯性 (Coherence):与疾病的自然史、流行病学数据不矛盾。
- 实验证据 (Experiment):干预(如戒烟)可降低风险。
- 类比 (Analogy):与其他已知因果关系类似。
希尔强调,这些标准不是数学公式,而是判断的辅助工具。没有一条是必须的,但综合考量可增强因果推断的信心。
5. 遗留的悖论:出生体重悖论
5.1 耶鲁夏米的发现
雅各布·耶鲁夏米(Jacob Yerushalmy)发现一个令人困惑的现象:吸烟母亲所生婴儿的平均出生体重较低,但低出生体重婴儿中,吸烟母亲的婴儿死亡率反而低于非吸烟母亲的婴儿。这似乎暗示吸烟对低出生体重婴儿有保护作用。
5.2 因果图解释(图5.4)
吸烟 (X) → 低出生体重 (M) → 死亡 (Y)
↑ ↑ ↑
\ \ \
\ \ \
\ \ \
\ \
\ \
\ \
\ \
\ \
\ \
\ \
\ \
\ \
\
未观测的出生缺陷 (U)
低出生体重 (M) 是一个对撞子 (collider),受吸烟 (X) 和未观测的出生缺陷 (U) 共同影响。
- 偏差机制:当我们仅研究低出生体重婴儿时,相当于条件于对撞子 M。这会在 X 和 U 之间打开一条非因果路径(因为 X 和 U 是 M 的原因,给定 M 后它们变得相关),而 U 又影响死亡 Y。因此,我们观察到一个虚假的负相关:吸烟母亲的孩子似乎死亡风险更低。
- 教训:出生体重悖论是对撞子偏差 (collider bias) 的典型案例,说明即使在没有混杂的情况下,错误的调整(或条件)也会引入偏差。
6. 与前后的联系
- 与第1-4章的联系:本章是前几章理论的实战演练。它用第1章的因果之梯框架(观察 vs 干预)分析吸烟问题;用第3章的对撞子结构解释出生体重悖论;用第4章的后门准则和混杂概念剖析费舍尔的假说。科恩菲尔德不等式实际上是敏感性分析的雏形,它告诉我们未测量混杂需要多强才能推翻因果结论。
- 与第6章的联系:出生体重悖论是第6章将要详述的众多悖论之一(如辛普森悖论、伯克森悖论),它们都源于对撞子或分层不当。
- 与第7章的联系:第7章将引入更强大的工具——后门调整公式和前门准则,这些工具可以直接应用于吸烟-肺癌问题,提供比科恩菲尔德不等式更精确的估计方法。
- 与第9章的联系:吸烟基因的研究(第9章将详述)进一步探讨了基因、吸烟和肺癌之间的中介和交互作用,这是对第5章遗留问题的深化。
7. 总结与重点
核心要点
- 观察性研究的挑战:在没有随机化的情况下,建立因果关系需要多种证据和逻辑推理。
- 费舍尔的混杂假说:他提出的“吸烟基因”是未测量混杂的典型案例,也是统计学家对因果推断抵制的体现。
- 科恩菲尔德不等式:为反驳混杂假说提供了数学工具,是敏感性分析的早期形式。它证明,要完全解释观测关联,未测量混杂必须强到不合理的程度。
- 多种证据的综合:病例对照研究、队列研究、剂量反应关系、生物合理性、戒烟效果等共同指向因果结论。
- 希尔标准:一套实用的因果评估准则,虽非数学公式,但为因果判断提供了框架。
- 出生体重悖论:揭示了条件于对撞子(collider)会引入偏差,强调了因果图在诊断偏差中的重要性。
常见难点
- 理解科恩菲尔德不等式的意义:它不是一个点估计,而是一个逻辑条件。它说明“即使存在未测量混杂,如果关联强度足够大,混杂也无法完全解释关联”。
- 区分对撞子与混杂:出生体重悖论是对撞子偏差,而非混杂。这提醒我们,控制错误的变量(或进行错误的分层)可能引入偏差,而不是消除偏差。
- 希尔标准的局限性:希尔标准不是严格的因果推断工具,而是启发式清单。不同研究者可能对同一条证据的权重有不同判断。
学习建议
- 动手计算:用科恩菲尔德不等式的数字例子(如相对风险9倍)验证其结论,理解不等式背后的逻辑。
- 画因果图:将费舍尔的假说、出生体重悖论用因果图表示,观察后门路径和对撞子结构。
- 对比 RCT 与观察研究:思考为什么 RCT 可以避免这些争论,而观察研究需要额外努力。
- 阅读原始文献:鼓励阅读多尔和希尔的原始论文,以及科恩菲尔德1959年的文章,感受历史中科学辩论的严谨。
第5章不仅是一段历史,更是因果推断方法论在现实问题中的精彩应用。它告诉我们,即使没有随机化,通过严谨的推理和多源证据,我们仍然可以接近因果真相。
《The Book of Why》第6章“Paradoxes Galore!”深度讲解
引言:悖论——因果思维的探照灯
本章题为“Paradoxes Galore!”,意为“悖论纷呈”。珀尔将带领我们穿越几个最著名、最令人困惑的概率与统计悖论:蒙提霍尔悖论 (Monty Hall Paradox)、伯克森悖论 (Berkson’s Paradox) 以及辛普森悖论 (Simpson’s Paradox)。这些悖论之所以令人困惑,是因为它们揭示了因果关系与纯统计关联之间的根本冲突。人类直觉本质上是因果性的,而数据只记录关联,当两者错位时,悖论便产生了。本章的核心目标是展示如何用因果图这把钥匙,轻松解开这些看似矛盾的谜题,从而深化对因果与统计关系的理解。
1. 基础概念:为什么会产生悖论?
- 统计关联 vs. 因果关系:
- 统计关联(相关)只告诉我们两个变量一起变化的模式,而不涉及方向或机制。
- 因果关系则涉及干预、机制和反事实。
- 直觉的因果性:人类大脑天生擅长因果推理,例如我们很自然地认为“原因早于结果”、“事件有原因”。这种直觉在处理纯统计问题时可能失效,因为统计关系可能由非因果机制(如对撞子偏差、混杂)产生。
- 悖论的根源:当一个统计现象与我们的因果直觉相冲突时,便产生了悖论。例如,在蒙提霍尔问题中,直觉认为剩下两扇门概率相等,但正确解却是2/3 vs 1/3,这违背了“无因果联系则概率相等”的直觉。
2. 蒙提霍尔悖论 (Monty Hall Paradox)
2.1 问题描述
你是游戏节目《Let’s Make a Deal》的参赛者,面前有三扇门:一扇后面是汽车,另两扇后面是山羊。你选择一扇(例如1号门)。主持人蒙提·霍尔(他知道门后情况)会打开另一扇有山羊的门(例如3号门),然后问你:“你想换成2号门吗?” 你该不该换?
2.2 直觉陷阱
许多人认为,剩下两扇门,汽车在其中一扇后面,所以换与不换的概率都是1/2。但正确答案是:换门获胜概率是2/3,不换是1/3。
2.3 因果图解释
- 变量:你的初始选择 $C$,汽车位置 $P$,主持人打开的门 $H$。
- 关系:
- $C$ 与 $P$ 独立(你随机选,车随机放)。
- $H$ 同时依赖于 $C$ 和 $P$:主持人必须打开一扇你没有选且不是车的门。因此,$H$ 是 对撞子 (collider):$C \rightarrow H \leftarrow P$。
- 信息更新:当你看到主持人打开3号门(且是山羊)时,你条件于对撞子 H。根据第3章的对撞子性质,条件于对撞子会使其父节点 $C$ 和 $P$ 之间产生非因果的依赖。具体来说:
- 如果你最初选对(概率1/3),主持人可以随机开剩下两扇有山羊的门之一。
- 如果你最初选错(概率2/3),主持人只剩一扇可选(另一扇有车的门不能开)。因此,当主持人打开3号门时,这提供了信息:你的初始选择更可能是错的(因为如果是对的,主持人开3号门的概率是1/2;如果是错的,主持人开3号门的概率是1)。通过贝叶斯更新,后验概率 $P(\text{车在2号门}) = 2/3$。
2.4 关键点:数据生成过程的重要性
如果规则改变——主持人随机开一扇不是你选的门(可能开到车),那么条件于对撞子就不再产生偏差。这强调了:统计数据的意义取决于数据生成过程,即因果结构。
3. 伯克森悖论 (Berkson’s Paradox)
3.1 问题描述
约瑟夫·伯克森(Joseph Berkson)发现,在医院的病人中,两种原本在人群中无关的疾病可能会表现出负相关。例如,糖尿病和胆囊炎在普通人群中独立,但在住院病人中可能呈现负相关。
3.2 因果图解释
- 变量:疾病 $A$,疾病 $B$,住院 $H$。
- 假设:$A$ 和 $B$ 在人群中独立,但两者都增加住院概率(例如 $A \rightarrow H$,$B \rightarrow H$)。因此 $H$ 是 $A$ 和 $B$ 的对撞子。
- 选择偏差:当我们研究住院病人时,我们条件于对撞子 H。这会使 $A$ 和 $B$ 产生负相关(解释-消失效应):如果病人因 $A$ 住院,那么他因 $B$ 住院的可能性降低,因为不需要两个原因同时存在才能住院(尤其当住院由任一疾病引起时)。
- 例子:如果住院只需要一种疾病,那么患有糖尿病的住院病人更不可能同时患有胆囊炎(否则两种都有,但并非必需)。这导致在医院数据中两种疾病负相关,尽管在人群中独立。
3.3 更一般的形式:选择偏差
伯克森悖论是选择偏差的一种典型表现,即研究样本的选择依赖于结果或原因,从而扭曲了真实的关系。
4. 辛普森悖论 (Simpson’s Paradox)
4.1 问题描述
辛普森悖论是指:当数据被分组时,每个组内呈现一种趋势(例如,处理组比对照组结果差),但当所有组合并时,趋势却反转(处理组比对照组结果好)。经典的例子是药物有效性:药物对男性无效甚至有害,对女性也无效甚至有害,但合并后却显示有效。这被称为“BBG”(bad for boys, bad for girls, good for people)悖论。
4.2 虚构数据示例
| 性别 | 对照组 (未服药) | 处理组 (服药) |
|---|---|---|
| 男 | 30% 心脏病 | 40% 心脏病 |
| 女 | 5% 心脏病 | 7.5% 心脏病 |
| 合计 | 22% 心脏病 | 18% 心脏病 |
- 在男女各自组内,服药组心脏病比例更高(药物有害)。
- 在合并数据中,服药组心脏病比例更低(药物有益)。
4.3 因果图解释
这种悖论的关键在于存在一个混杂因子——性别。性别同时影响是否服药和心脏病风险。例如,男性更倾向于不服药(对照组比例高),但男性本身心脏病风险高;女性更倾向于服药(处理组比例高),但女性本身心脏病风险低。
- 无混杂情况:如果性别不影响服药,则数据不会出现悖论。
- 解决:要估计服药的真实因果效应,需要控制性别,即计算性别分层后的加权平均。根据后门准则(第4章),调整性别后的因果效应应为:
代入数据:
- 男性:服药组心脏病率40%,未服药30%,差+10%(有害)
- 女性:服药组7.5%,未服药5%,差+2.5%(有害)
- 加权平均:若男女各占一半,则因果效应 = (0.4+0.075)/2 - (0.3+0.05)/2 = 0.2375 - 0.175 = 0.0625(有害)。因此药物实际有害,合并数据的有益假象是由于女性在服药组占比过高且本身风险低造成的。
4.4 萨维奇确信原则 (Savage’s Sure-Thing Principle)
- 定义:如果你在事件 $C$ 发生时会选择行动 $A$,在 $C$ 不发生时会选择行动 $A$,那么你应该选择行动 $A$,即使你不知道 $C$ 是否发生。
- 因果修正:该原则成立的前提是你的行动不会影响 $C$ 的概率。在辛普森悖论中,性别 ($C$) 不受服药 ($A$) 影响,因此如果你在男性和女性中都发现药物有害,那么药物在总体中必然有害。因此,BBG药物不可能存在,悖论的出现正是因为我们在分析时错误地合并了数据,而没有意识到性别分布差异。
4.5 何时合并?何时分层?
答案取决于因果结构:
- 如果第三变量是混杂因子(如性别影响服药和结果),则应分层。
- 如果第三变量是中介(如服药影响血压,血压影响心脏病),则应合并(控制中介会阻断因果路径)。
- 如果第三变量是对撞子,则分层会引入偏差。
例子:如果研究的是“血压”作为第三变量,且服药通过降低血压来减少心脏病,那么血压是中介。此时合并数据(不控制血压)给出总效应,分层(控制血压)给出直接效应,两者意义不同。
5. 洛德悖论 (Lord’s Paradox)
5.1 问题描述
洛德(Lord)提出一个关于大学饮食计划对学生体重影响的悖论。假设学生入学时体重 ($W_1$) 和学年结束时体重 ($W_2$) 被测量。数据分为两个餐厅(饮食 A 和饮食 B)。两个统计学家得到不同结论:
- 统计学家1:比较平均体重变化 $W_2 - W_1$,发现两个餐厅无差异。
- 统计学家2:比较相同入学体重 $W_1$ 下的最终体重 $W_2$,发现餐厅 B 的学生体重增加更多。
5.2 因果图解释
- 变量:餐厅类型 $D$(A或B),入学体重 $W_1$,最终体重 $W_2$。
- 可能因果结构:
- 混杂:如果学生根据入学体重选择餐厅,则 $W_1$ 是混杂因子(影响 $D$ 和 $W_2$)。此时,统计学家2控制 $W_1$ 是正确的,统计学家1得到的总效应可能被混杂掩盖。
- 中介:如果餐厅选择影响体重变化,且入学体重是基线测量(不受餐厅影响),则 $W_1$ 可能是前处理变量,不一定是混杂。此时,统计学家1的总效应是因果效应,统计学家2控制 $W_1$ 得到的是直接效应(可能因 $W_1$ 与 $D$ 无关而不需要控制)。
珀尔指出,洛德悖论的关键在于确定 $W_1$ 与 $D$ 的关系。因果图可以明确展示这种关系,从而决定应该用哪种分析。
6. 概念关系图
7. 与前后的联系
- 与第3章的联系:三种基本连接(链、叉、对撞子)是理解悖论的基础。蒙提霍尔和伯克森悖论直接源于对撞子性质。
- 与第4章的联系:辛普森悖论是混杂问题的典型案例,需要用后门准则解决。洛德悖论涉及前处理变量的处理,与第4章的后门准则和第9章的中介分析相关。
- 与第5章的联系:出生体重悖论是伯克森悖论的一种形式(对撞子偏差),第5章已提及。
- 与后续章节的联系:
- 第7章将介绍更强大的工具(后门调整、前门准则),可直接用于解决这些悖论中的因果估计问题。
- 第9章中介分析将处理洛德悖论中“直接效应”与“总效应”的区别。
8. 总结与重点
核心要点
- 悖论源于因果直觉与统计关联的冲突。人类天生用因果思维理解世界,而数据只记录关联。
- 对撞子结构是许多悖论的根源:条件于对撞子会产生虚假相关(蒙提霍尔、伯克森、出生体重悖论)。
- 辛普森悖论的核心是混杂:需要根据因果图决定是分层还是合并。萨维奇确信原则提供了因果条件。
- 洛德悖论提醒我们:分析前必须明确变量间的因果角色(混杂、中介、前处理变量)。
- 通用解决方案:因果图 + 后门准则 + do-算子,可以明确回答何时分层、何时合并,从而准确估计因果效应。
常见难点
- 对撞子的反直觉性:为什么控制一个变量会引入相关?需要反复练习,如“天赋与美貌”的例子。
- 辛普森悖论中何时分层:不能仅凭数据,必须依赖因果图。如果第三变量是混杂,则分层;如果是中介,则合并。
- 混淆“条件概率”与“干预概率”:悖论常出现在将 $P(Y|X)$ 误解为 $P(Y|do(X))$ 时。用 do-算子可以澄清。
学习建议
- 画因果图:对每个悖论,自己画出因果图,标出变量和箭头。
- 动手计算:对蒙提霍尔和辛普森例子,手动进行概率计算,验证悖论结果。
- 联系实际:思考生活中是否有类似悖论(如名校录取的性别差异、治疗效果的分层矛盾),尝试用因果图分析。
- 阅读扩展:本章提到的萨维奇确信原则在决策理论中有广泛应用,可进一步了解。
第6章不仅是娱乐性的悖论集锦,更是对因果思维必要性的有力证明。掌握这些悖论的因果解法,将使你成为更清醒的数据解释者。
《The Book of Why》第7章“Beyond Adjustment: The Conquest of Mount Intervention”深度讲解
引言:攀登干预之峰
第7章将我们带入因果推断的核心战场——如何从观测数据中估计干预效应 $ P(Y|do(X)) $。在第4章中,我们学习了后门准则,它告诉我们当存在可测量的混杂因子时,如何通过调整它们来消除偏差。然而,现实世界中,混杂因子可能未观测或不可测量,后门准则可能失效。本章将介绍更强大的工具:前门准则、工具变量以及通用的do-演算。这些方法使我们能够“攀登干预之峰”,即使在复杂情况下也能估计因果效应。
1. 基础概念回顾
1.1 干预效应 (Interventional Effect)
- 定义:$ P(Y|do(X)) $ 表示在系统中强制将 $X$ 设为特定值后,$Y$ 的概率分布。
- 与观察分布的区别:$ P(Y|X) $ 反映的是看到 $X$ 时的条件概率,可能包含混杂偏差;$ P(Y|do(X)) $ 是因果效应,需要去除所有非因果路径的影响。
1.2 后门准则 (Back-door Criterion)
- 条件:一组变量 $Z$ 满足后门准则,如果它阻断了所有从 $X$ 到 $Y$ 的后门路径(即指向 $X$ 的路径),并且 $Z$ 中不包含 $X$ 的后代。
- 调整公式:若 $Z$ 满足后门准则,则 $$ P(Y|do(X)) = \sum_z P(Y|X, Z=z) P(Z=z) $$
- 局限性:当混杂因子未观测时,后门准则无法应用。
2. 前门准则 (Front-door Criterion)
2.1 问题背景
考虑吸烟与肺癌的例子:可能存在未观测的“吸烟基因”同时导致吸烟和肺癌(混杂)。但如果我们能找到一个中介变量 $M$(如焦油沉积),且满足以下条件:
- $X$ 对 $Y$ 的全部影响都通过 $M$ 传递(即 $X \rightarrow M \rightarrow Y$,且无直接路径)。
- 中介 $M$ 与任何混杂因子 $U$ 之间没有关联(即 $M$ 不受 $U$ 影响,或 $U$ 对 $M$ 的影响被阻断)。
- 不存在从 $U$ 到 $M$ 的路径,且 $M$ 与 $Y$ 之间的关联未被 $U$ 混淆。
2.2 前门准则定义
珀尔提出的前门准则允许我们利用这样的中介变量来估计因果效应,即使存在未观测混杂。其调整公式为:
$$ P(Y|do(X)) = \sum_m P(M=m|X) \sum_{x'} P(Y|X=x', M=m) P(X=x') $$解释:
- 第一项 $P(M=m|X)$ 是 $X$ 对 $M$ 的效应(可直接观测)。
- 第二项 $\sum_{x'} P(Y|X=x', M=m) P(X=x')$ 是 $M$ 对 $Y$ 的效应,通过对 $X$ 进行调整(因为 $X$ 可能同时影响 $M$ 和 $Y$,但 $X$ 是观测的)。
- 整个公式相当于:先估计 $X$ 对 $M$ 的效应,再估计 $M$ 对 $Y$ 的效应(控制 $X$),然后通过 $M$ 将两者结合。
2.3 实例:吸烟、焦油与肺癌
- 假设:吸烟 ($X$) 通过焦油沉积 ($M$) 导致肺癌 ($Y$),且存在未观测的基因 $U$ 同时影响 $X$ 和 $Y$(但不影响 $M$)。见图7.1。
- 数据:我们可观测 $X$、$M$、$Y$,但无法观测 $U$。
- 应用前门公式:
- 从数据估计 $P(M|X)$(吸烟对焦油的影响)。
- 从数据估计 $P(Y|X, M)$(在给定吸烟下,焦油对肺癌的影响),然后对 $X$ 加权平均。
- 组合得到 $P(Y|do(X))$。
- 结果:即使存在未观测混杂,我们仍能估计吸烟的因果效应。
2.4 应用实例:职业培训研究 (Glynn & Kashin, 2014)
- 问题:评估职业培训计划 ($X$) 对收入 ($Y$) 的影响。存在未观测动机 ($U$) 影响报名和收入。
- 中介:是否实际参与培训 ($M$)。假设动机不影响参与(即 $U$ 与 $M$ 无直接关联)。
- 结果:前门估计与随机对照试验结果一致,证明方法有效。
3. 工具变量 (Instrumental Variables)
3.1 基本思想
当存在未观测混杂时,如果能找到一个变量 $Z$,它满足:
- $Z$ 与 $X$ 相关($Z$ 影响 $X$)。
- $Z$ 对 $Y$ 的影响完全通过 $X$(即无直接路径 $Z \rightarrow Y$)。
- $Z$ 与任何混杂因子 $U$ 独立(无后门路径连接 $Z$ 和 $Y$ 除了通过 $X$)。
那么 $Z$ 称为工具变量。利用工具变量,可以估计 $X$ 对 $Y$ 的因果效应,即使 $U$ 未观测。
3.2 线性模型中的工具变量估计
假设线性结构:
$$ X = a Z + u,\quad Y = b X + v $$其中 $u, v$ 包含未观测混杂(可能相关)。工具变量 $Z$ 与 $u, v$ 独立。 则:
$$ \text{Cov}(Z,Y) = b \cdot \text{Cov}(Z,X) $$因此:
$$ b = \frac{\text{Cov}(Z,Y)}{\text{Cov}(Z,X)} $$在样本中,可用回归系数估计:
$$ \hat{b} = \frac{\hat{r}_{ZY}}{\hat{r}_{ZX}} $$其中 $\hat{r}$ 是相关系数或回归系数。
3.3 实例:约翰·斯诺的霍乱研究
- 问题:确定受污染的水 ($X$) 是否导致霍乱 ($Y$)。存在混杂(如贫穷、卫生条件 $U$)。
- 工具变量:供水公司 ($Z$)。在伦敦某些地区,两家公司混合供水,居民用水来源近乎随机。斯诺发现,使用南华克公司(水源受污染)的家庭霍乱死亡率远高于使用兰贝斯公司(水源清洁)的家庭。
- 因果图:$Z \rightarrow X \rightarrow Y$,且 $Z$ 与 $U$ 独立。
- 结论:斯诺通过比较两个供水公司,证明了受污染水是霍乱的原因。
3.4 非参数工具变量与单调性
- 在非线性或非参数模型中,工具变量不一定给出点估计,但可给出界限。例如,在药物依从性研究中,随机分配 ($Z$) 是工具变量,但患者可能不依从 ($X$)。通过假设单调性(无人反向依从),可得到因果效应的范围。
4. do-演算 (do-calculus)
4.1 动机
前门准则和工具变量都是特定情况下的方法。是否存在一个通用的规则系统,可以判断给定因果图下,$P(Y|do(X))$ 是否可由观测数据识别,并给出计算公式?珀尔提出的do-演算正是这样的系统。
4.2 三条基本规则
do-演算包含三条规则,用于对含 $do$ 的概率表达式进行变换,逐步消除 $do$ 算子,直到表达式完全由观测概率组成。每条规则依赖于因果图的结构,通过检查图中的条件独立性来确定变换是否合法。
规则1(增加/删除观察): 如果给定 $Z$ 和 $W$,$Y$ 与 $W$ 条件独立(在删除指向 $X$ 的箭头后的图中),则
$$ P(Y|do(X), Z, W) = P(Y|do(X), Z) $$规则2(干预与观察互换): 如果给定 $Z$,$Y$ 与 $X$ 条件独立(在删除所有指向 $X$ 的箭头后的图中,同时保持其他箭头),则
$$ P(Y|do(X), Z) = P(Y|X, Z) $$这实际上是后门准则的推广。
规则3(删除干预): 如果从 $X$ 到 $Y$ 没有因果路径(即所有路径都被阻断),则
$$ P(Y|do(X)) = P(Y) $$这些规则允许我们通过一系列变换,将目标表达式转化为可观测的表达式。
4.3 应用:前门公式的推导
利用 do-演算,可以系统推导出前门公式。过程涉及多次应用规则1-3,逐步消除 $do(X)$,最终得到仅含观测概率的表达式。
4.4 完备性
Shpitser 和 Pearl (2006) 证明了这三条规则是完备的:只要 $P(Y|do(X))$ 可由观测数据识别,就存在一个有限序列的规则应用将其转化为无 $do$ 的表达式。这为因果识别提供了理论基础。
4.5 实例:M-bias 图与 do-演算
- 图结构:$X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$,且 $X \rightarrow Y$ 存在。
- 问题:能否识别 $P(Y|do(X))$?
- 分析:后门路径 $X \leftarrow A \rightarrow B \leftarrow C \rightarrow Y$ 被对撞子 $B$ 阻断,因此不需要控制。但 $X$ 与 $Y$ 有直接路径,因此干预效应等于观察关联?实际上,由于直接路径存在,且无后门路径,$P(Y|do(X)) = P(Y|X)$。do-演算可验证。
5. 概念关系图
需观测混杂] C[前门准则
需观测中介] D[工具变量
需工具变量 Z] E[do-演算
通用系统] end subgraph 条件 B1[存在可观测的 Z 满足后门准则] C1[存在中介 M 满足前门条件] D1[存在 Z 满足工具变量条件] end A --> B & C & D & E B --> B1 C --> C1 D --> D1 E --> 可判断可识别性并给出公式 subgraph 实例 F[吸烟-肺癌:前门] G[霍乱:工具变量] H[职业培训:前门] I[M-bias:do-演算] end C --> F & H D --> G E --> I
6. 与前后的联系
- 与第4章的联系:后门准则是基础,前门准则和工具变量是在后门无法应用时的替代方案。
- 与第5章的联系:吸烟-肺癌辩论中,科恩菲尔德不等式是敏感性分析,而前门准则提供了更精确的估计方法(如果焦油可测量)。
- 与第6章的联系:悖论中的许多问题(如辛普森悖论)可通过后门或前门解决。
- 与第8章的联系:do-演算是处理干预的基础,第8章将进入反事实层面,需要更复杂的工具。
- 与第9章的联系:中介分析(前门准则)是中介效应的特例,第9章将详细讨论直接与间接效应。
7. 总结与重点
核心要点
- 后门准则:当存在可观测混杂时,通过调整消除偏差。
- 前门准则:当存在可观测中介且满足特定条件时,即使存在未观测混杂也能估计因果效应。
- 工具变量:当存在一个与 $X$ 相关、与 $Y$ 无直接联系且与混杂独立的变量时,可估计因果效应(尤其在线性模型中)。
- do-演算:一套完备的规则系统,用于判断干预效应是否可识别,并推导出估计公式。
- 可识别性:一个因果效应是可识别的,当且仅当它能从观测数据中唯一确定,无论未观测因素如何分布。
常见难点
- 前门准则的直观理解:需要理解为什么通过中介可以绕过未观测混杂。关键在于中介 $M$ 与 $U$ 无关联,因此 $X \rightarrow M$ 的效应无混杂,而 $M \rightarrow Y$ 的效应可通过控制 $X$ 来消除混杂(因为 $X$ 是 $M$ 的原因,但 $X$ 本身可能受 $U$ 影响,但控制 $X$ 后 $M$ 与 $Y$ 的关系就干净了?需仔细解释)。
- 工具变量的有效性假设:工具变量必须与混杂独立且无直接路径,这些假设通常无法从数据检验,需依靠领域知识。
- do-演算的抽象性:初学者可能觉得规则复杂,但关键是理解每条规则对应的图形条件。
学习建议
- 画图练习:对每个方法,画出对应的因果图,标注变量关系。
- 推导公式:尝试用 do-演算推导前门公式,体会规则的应用。
- 实例分析:阅读约翰·斯诺的故事,思考为什么供水公司是工具变量。
- 结合软件:一些因果推断软件(如 DAGitty、causalnex)可自动应用 do-演算,可尝试用它们分析简单图。
第7章为我们提供了攀登干预之峰的工具箱。掌握这些方法,我们就能在复杂现实中更接近因果真相。
《The Book of Why》第8章“Counterfactuals: Mining Worlds That Could Have Been”深度讲解
引言:因果之梯的顶端
第8章带领我们攀登到因果之梯的第三层——反事实。这一层回答的是那些最深刻的问题:“如果当初……会怎样?”以及“为什么?”。反事实思维是人类独有的能力,它使我们能够从历史中学习、追究责任、感受后悔,并设想不同的未来。本章将展示如何用数学和算法来处理反事实问题,使机器也能拥有这种“想象”能力。
1. 基础概念:什么是反事实?
1.1 定义
反事实是指:在已知事实(观察到 $X=x$ 且 $Y=y$)的情况下,想象如果 $X$ 取另一个值 $x'$,那么 $Y$ 会取什么值。记作 $Y_{X=x'}(u)$,即在个体 $u$ 上,若 $X$ 被设为 $x'$,$Y$ 的取值。
1.2 哲学渊源
- 大卫·休谟 (David Hume):他在《人性论》中提出了因果的“规律性”定义,但在后来的《人类理解研究》中补充了反事实定义:“如果第一个对象不曾存在,第二个对象也绝不存在。”这表明反事实是因果的核心。
- 大卫·刘易斯 (David Lewis):他主张用“可能世界”理论解释反事实,即“如果 $A$ 发生,则 $B$ 发生”意味着在那些与真实世界最相似的、$A$ 成立的可能世界中,$B$ 也成立。虽然刘易斯认为这些世界是真实存在的,但珀尔强调,我们只需在头脑中模拟这些世界,而因果图提供了模拟的规则。
1.3 反事实与干预的区别
- 干预:$P(Y|do(X=x))$ 问的是:如果对整个群体实施 $X=x$,$Y$ 的分布如何?它是前瞻性的,不依赖于个体已观测到的结果。
- 反事实:$P(Y_{X=x'}=y | X=x, Y=y)$ 问的是:对于某个已观测到特定结果的个体,如果他当初接受的是另一种处理,他的结果会如何?它是回溯性的,需要结合个体已观测信息。
2. 核心框架:潜在结果与结构因果模型
2.1 鲁宾因果模型 (Rubin Causal Model, RCM) 与潜在结果
鲁宾将反事实称为潜在结果 (potential outcomes)。对于每个个体 $u$,有两个潜在结果:$Y_{X=1}(u)$ 和 $Y_{X=0}(u)$,分别表示接受处理和不接受处理时的结果。我们只能观测到其中一个。
- 符号:$Y_x(u)$ 表示个体 $u$ 在 $X=x$ 下的潜在结果。
- 个体因果效应:$Y_1(u) - Y_0(u)$。
- 平均因果效应 (ATE):$E[Y_1 - Y_0]$。
- 处理组的平均处理效应 (ATT):$E[Y_1 - Y_0 | X=1]$。
核心问题:由于每个个体只有一个潜在结果可观测,我们无法直接知道个体因果效应。这被称为因果推断的基本问题。
2.2 结构因果模型 (Structural Causal Model, SCM)
珀尔的结构因果模型提供了一个计算反事实的系统性方法。一个SCM由三部分组成:
- 外生变量 (exogenous variables) $U$:不受模型内其他变量影响的背景因素(如个体的遗传、环境)。
- 内生变量 (endogenous variables) $V$:模型内由其他变量决定的变量,每个内生变量由一个结构方程定义: $$ V_i = f_i(pa_i, U_i) $$ 其中 $pa_i$ 是 $V_i$ 的父节点(直接原因),$U_i$ 是影响 $V_i$ 的外生变量。
- 因果图:表示变量间的依赖关系。
2.3 反事实的三步算法
给定一个SCM和观测到的证据 $E$(例如 $X=x, Y=y$),要计算反事实概率 $P(Y_{X=x'}=y' | E)$,珀尔提出了三步法:
- 吸收 (Abduction):利用观测证据 $E$ 更新外生变量 $U$ 的分布,得到后验分布 $P(U | E)$。这一步相当于根据已发生的事实推断出个体可能的外生特征。
- 行动 (Action):对模型进行干预,将 $X$ 设为反事实值 $x'$,即用 $do(X=x')$ 替换结构方程中 $X$ 的原始方程,得到修改后的模型 $M_{x'}$。
- 预测 (Prediction):在修改后的模型 $M_{x'}$ 中,利用更新后的外生变量分布 $P(U | E)$ 计算目标变量 $Y$ 的值,得到反事实分布。
数学表达:
$$ P(Y_{X=x'}=y' | E) = \int_{U} \mathbf{1}_{Y_{x'}(u)=y'} dP(u | E) $$例子:行刑队(第1章):
- 观测:囚犯死亡 ($D=1$),且士兵A开枪 ($A=1$)。
- 反事实问题:如果士兵A没开枪 ($do(A=0)$),囚犯还会死吗?
- 吸收:根据观测,推断出上尉一定发了信号 ($C=1$),士兵B一定开枪 ($B=1$)。(假设确定性模型)
- 行动:删除 $A$ 的方程,设 $A=0$。
- 预测:在修改后的模型中,$B=1$ 仍成立,所以 $D=1$。结论:囚犯仍会死。
3. 线性模型中的反事实
在线性结构方程模型中,反事实计算尤为简单。假设:
$$ X = a U + \epsilon_X,\quad Y = b X + c U + \epsilon_Y $$其中 $U$ 是未观测混杂,$\epsilon$ 是独立误差。
给定观测到 $X=x, Y=y$,要计算 $Y_{X=x'}$(如果 $X$ 设为 $x'$ 时的 $Y$):
- 吸收:从观测推断出 $U$ 的值(或分布)。在线性模型中,可用回归得到 $U$ 的条件分布。
- 行动:将 $X$ 设为 $x'$。
- 预测:计算 $Y' = b x' + c \hat{U} + \epsilon_Y$(其中 $\hat{U}$ 是 $U$ 的估计)。
例子:教育、经验与薪水(表8.1,图8.3):
- 结构方程: $$ \text{EX} = 10 - 4 \times \text{ED} + U_{\text{EX}},\quad \text{S} = 65000 + 2500 \times \text{EX} + 5000 \times \text{ED} + U_{\text{S}} $$
- 观测:爱丽丝:$\text{ED}=0, \text{EX}=6, \text{S}=?$(实际给的是 $S$?假设我们观测到 $S$)。
- 吸收:由 $\text{EX}=6$ 得 $U_{\text{EX}} = 6 - (10 - 0) = -4$;由 $S$ 得 $U_S$ 的值。
- 行动:设 $\text{ED}=1$。
- 预测:先算 $\text{EX}' = 10 - 4 \times 1 - 4 = 2$;再算 $\text{S}' = 65000 + 2500 \times 2 + 5000 \times 1 + U_S$。
4. 概率的因果:必要与充分原因
在许多应用中,我们关心的是个体层面上事件的责任归属。珀尔定义了两种概率度量:
必要原因的概率 (Probability of necessity, PN):对于已发生的 $X=1$ 和 $Y=1$,问“如果 $X$ 不曾发生,$Y$ 还会发生吗?”即
$$ PN = P(Y_{X=0}=0 | X=1, Y=1) $$它衡量 $X$ 对 $Y$ 的必要性:没有 $X$ 就没有 $Y$。
充分原因的概率 (Probability of sufficiency, PS):对于未发生的 $X=0$ 和 $Y=0$,问“如果 $X$ 发生,$Y$ 会发生吗?”即
$$ PS = P(Y_{X=1}=1 | X=0, Y=0) $$它衡量 $X$ 对 $Y$ 的充分性:有 $X$ 就有 $Y$。
必要且充分原因的概率 (Probability of necessity and sufficiency, PNS):
$$ PNS = P(Y_{X=1}=1, Y_{X=0}=0) $$它表示 $X$ 既是必要的又是充分的概率(即 $X$ 真正因果地导致 $Y$)。
例子:火柴与氧气:
- 房子着火 ($Y=1$),有人划了火柴 ($X=1$)。氧气存在 ($Z$ 通常存在) 也是必要的。但 PN(火柴) 高(因为没火柴可能不着),PS(火柴) 也高(划火柴通常会导致着火,如果氧气存在)。而氧气的 PN 也高(没有氧气着火不会发生),但 PS 低(因为氧气本身不导致着火)。这解释了为什么我们更倾向于将火柴视为原因。
5. 应用实例
5.1 法律中的“但-因”因果
- 法律标准:被告的行为是伤害的“但-因” (but-for cause),即如果没有该行为,伤害不会发生。这正是 PN 的定义。
- 例子:被告枪击受害者致死。已知 $X=1, Y=1$。PN 是“如果被告未开枪,受害者还活着”的概率。如果 PN > 0.5,则可能满足“优势证据”标准。
- 复杂性:可能存在多个充分原因(如两个枪手同时开枪)。此时 PN 可能很低,但 PS 很高。法律上需考虑“近因”等概念。
5.2 气候变化归因
- 问题:2003年欧洲热浪是否由人为气候变化引起?
- 方法:用气候模型模拟两个世界:有温室气体排放的现实世界 ($X=1$) 和无排放的假设世界 ($X=0$)。比较热浪发生概率。
- 计算:PN 为在现实世界中热浪发生的情况下,无排放世界不发生热浪的概率。Allen & Stott 估计 PN ≈ 0.9,即人为排放是热浪的必要原因概率为90%。
- 意义:这种量化归因比“不能归因于单个事件”的传统说法更有力,有助于公共政策。
6. 概念关系图
7. 与前后的联系
- 与第1章的联系:第1章引入了因果之梯,反事实是第三层。行刑队例子已展示反事实推理。
- 与第4章的联系:混杂问题影响反事实估计。SCM中的三步法需要正确模型。
- 与第7章的联系:干预($do$)是反事实的第二步“行动”的核心。do-演算用于处理干预,而反事实需要结合吸收。
- 与第9章的联系:中介分析涉及反事实,如自然直接效应 $NDE = P(Y_{1,M_0}=1) - P(Y_{0,M_0}=1)$,这正是反事实概念。
8. 总结与重点
核心要点
- 反事实是因果思维的最高层:它回答“如果……会怎样”,是学习、责任和想象的基础。
- 结构因果模型提供统一框架:通过三步法(吸收、行动、预测),可从观测数据和模型计算出反事实概率。
- 潜在结果框架是等价表述:鲁宾的潜在结果与SCM在数学上等价,但SCM提供因果图,便于表达假设。
- PN、PS、PNS 量化了个体层面因果关系的必要性和充分性,在法律和归因中有重要应用。
- 反事实与干预的区别:干预不依赖个体已观测结果,反事实依赖。
常见难点
- 吸收步骤的意义:吸收是利用观测数据更新对外生变量的信念,使得反事实预测符合该个体的特定情况。这相当于在给定事实下,推断出个体的“类型”。
- 线性模型中的计算:初学者可能混淆回归系数与结构系数。结构系数才是因果的。
- PN与PS的区别:PN关注已发生事件,PS关注未发生事件。两者结合可全面描述因果关系。
学习建议
- 多画因果图:对每个例子,画出SCM,标出内生、外生变量。
- 手动计算三步法:从简单确定性问题(行刑队)开始,再到线性模型(教育-薪水),体会吸收的作用。
- 应用实例分析:阅读法律和气候变化例子,思考如何用PN/PS表达结论。
- 联系其他章节:反事实是许多高级话题的基础,注意它在中介分析中的角色。
第8章赋予我们“挖掘可能世界”的能力,使因果推断从群体层面深入到个体层面,为人工智能和科学发现开辟了新天地。
《The Book of Why》第9章“Mediation: The Search for a Mechanism”深度讲解
引言:为什么需要中介分析?
在前几章中,我们已经学会了如何判断一个变量 $X$ 是否导致另一个变量 $Y$,以及如何估计 $X$ 对 $Y$ 的因果效应。然而,科学探索往往不满足于此。当我们知道吸烟导致肺癌后,我们还想知道:吸烟是如何导致肺癌的? 是通过焦油沉积?还是通过炎症?还是其他机制?这种对“如何”的追问,正是中介分析的核心。
中介分析旨在揭示原因 $X$ 影响结果 $Y$ 的内在机制,即是否存在一个中介变量 $M$,使得 $X$ 通过影响 $M$ 进而影响 $Y$。理解机制不仅满足求知欲,更具有实际意义:如果我们知道焦油是中介,那么开发低焦油香烟就可能降低肺癌风险;如果我们知道维生素C是中介,那么即使没有柑橘,我们也能通过补充维生素C预防坏血病。
1. 基础概念
1.1 中介变量 (Mediator)
- 定义:一个变量 $M$ 被称为中介变量,如果它位于因果路径 $X \rightarrow M \rightarrow Y$ 上,即 $X$ 通过影响 $M$ 来影响 $Y$。
- 因果图表示:$X \rightarrow M \rightarrow Y$,可能有额外的直接路径 $X \rightarrow Y$ 表示不通过 $M$ 的影响。
- 例子:在吸烟与肺癌的例子中,焦油沉积可能是中介变量;在教育与收入的例子中,工作经验可能是中介变量。
1.2 直接效应 (Direct Effect) 与间接效应 (Indirect Effect)
- 直接效应:$X$ 对 $Y$ 的影响中,不通过中介变量 $M$ 的那部分。在图中对应路径 $X \rightarrow Y$。
- 间接效应:$X$ 对 $Y$ 的影响中,通过中介变量 $M$ 的那部分。在图中对应路径 $X \rightarrow M \rightarrow Y$。
- 总效应:直接效应与间接效应之和(在线性模型中成立)。
1.3 线性模型中的中介分析
如果所有变量之间的关系是线性的,我们可以用路径系数来表示效应大小。设:
$$ M = a X + \epsilon_M,\quad Y = b M + c X + \epsilon_Y $$其中 $a$ 是 $X$ 对 $M$ 的效应,$b$ 是 $M$ 对 $Y$ 的效应(控制 $X$),$c$ 是 $X$ 对 $Y$ 的直接效应。那么:
- 间接效应 = $a \times b$
- 直接效应 = $c$
- 总效应 = $c + a b$
这种方法由 Sewall Wright 的路径分析开创,后由 Baron 和 Kenny (1986) 推广,成为社会科学中引用率最高的方法之一。
Baron-Kenny 方法步骤:
- 证明 $X$ 与 $Y$ 相关(总效应存在)。
- 证明 $X$ 与 $M$ 相关(路径 $a$ 存在)。
- 证明在控制 $X$ 后,$M$ 与 $Y$ 相关(路径 $b$ 存在)。
- 比较总效应与直接效应:若控制 $M$ 后 $X$ 对 $Y$ 的效应(即 $c$)变为零,则完全中介;若减小但不为零,则部分中介。
局限性:该方法假设线性、无交互作用、无测量误差,且要求正确设定中介方向。更重要的是,它无法处理非线性和交互的情况。
2. 非线性世界中的挑战:反事实介入
当模型非线性或存在交互时,直接效应和间接效应不再能简单地用路径系数乘积表示。例如,可能存在阈值效应:只有达到一定剂量才有效;或者交互作用:中介的效果依赖于 $X$ 的水平。此时,我们需要借助反事实来精确定义直接和间接效应。
2.1 受控直接效应 (Controlled Direct Effect, CDE)
- 定义:将中介 $M$ 固定在一个常数值 $m$,然后比较 $X=1$ 与 $X=0$ 时的结果差异: $$ CDE(m) = P(Y=1 | do(X=1), do(M=m)) - P(Y=1 | do(X=0), do(M=m)) $$
- 意义:它回答“如果我们将所有人(无论其 $X$ 值如何)的中介都设为同一水平 $m$,那么改变 $X$ 会产生多大影响?”这对应于将中介的路径阻断后,$X$ 的剩余影响。
- 缺点:$m$ 的选择可能任意,且不同的 $m$ 会得到不同的 CDE。此外,它要求我们能同时干预 $X$ 和 $M$,这在现实中往往不可行。
2.2 自然直接效应 (Natural Direct Effect, NDE)
- 定义:比较两种情形:
- 情形A:$X$ 设为 1,中介 $M$ 取其在 $X=0$ 时的自然值 $M_0$(即不因 $X$ 的改变而改变)。
- 情形B:$X$ 设为 0,中介 $M$ 取其在 $X=0$ 时的自然值 $M_0$。 $$ NDE = P(Y_{1, M_0} = 1) - P(Y_{0, M_0} = 1) $$ 其中 $Y_{x, M_0}$ 表示先设 $X=x$,但将 $M$ 固定为它在 $X=0$ 时本该取的值(无论 $x$ 是多少)。
- 直观理解:NDE 衡量的是,如果我们将所有人的中介水平保持在他们不处理时的水平(即阻断间接路径),那么处理带来的效果有多大。这反映了纯粹的直接效应,不依赖于中介的变化。
2.3 自然间接效应 (Natural Indirect Effect, NIE)
- 定义:比较两种情形:
- 情形A:$X$ 设为 0,中介 $M$ 取其在 $X=1$ 时的自然值 $M_1$。
- 情形B:$X$ 设为 0,中介 $M$ 取其在 $X=0$ 时的自然值 $M_0$。 $$ NIE = P(Y_{0, M_1} = 1) - P(Y_{0, M_0} = 1) $$
- 直观理解:NIE 衡量的是,如果我们将所有人的处理状态固定在未处理,但将他们的中介水平提高到处理状态应有的水平,那么结果的变化有多大。这反映了通过中介的间接效应。
重要关系:在线性无交互模型中,有 $TE = NDE + NIE$(总效应 = 自然直接 + 自然间接)。但在非线性或有交互时,这一等式不一定成立,但有其他分解形式。
2.4 中介公式 (Mediation Formula)
在满足一定假设(如无未测量的中介-结果混杂)下,NDE 和 NIE 可以从观测数据中估计,无需实际干预。公式如下(以离散情况为例):
$$ NDE = \sum_m [P(Y=1 | X=1, M=m) - P(Y=1 | X=0, M=m)] \times P(M=m | X=0) $$$$ NIE = \sum_m [P(M=m | X=1) - P(M=m | X=0)] \times P(Y=1 | X=0, M=m) $$解释:
- NDE 是对所有可能的 $m$,计算在给定 $m$ 下 $X$ 对 $Y$ 的效应(控制 $m$),然后按 $X=0$ 时 $M$ 的分布加权平均。这相当于将中介固定在其自然基线水平。
- NIE 是对所有可能的 $m$,计算 $X$ 对 $M$ 的效应(即 $P(M=m|X=1) - P(M=m|X=0)$),然后乘以在 $X=0$ 时该 $m$ 下的结果概率,最后求和。这相当于在保持 $X$ 为 0 的条件下,通过改变 $M$ 的分布来模拟间接效应。
条件:这些公式成立需要无混淆的中介-结果关系,即给定 $X$ 时,$M$ 与 $Y$ 之间无未观测混杂。因果图可以帮助检验这一条件。
3. 历史与当代案例
3.1 Barbara Burks 与智力遗传研究 (1926)
- 问题:智力是先天遗传(nature)还是后天环境(nurture)决定的?
- 因果图:父母智力 → 子女智力(直接路径),父母智力 → 社会地位 → 子女智力(间接路径)。社会地位是中介。
- 贡献:Burks 是最早使用路径图的研究者之一,她意识到控制中介(社会地位)会导致偏差,因为中介是受父母智力影响的变量。这预示了后来对中介分析的深入理解。
3.2 伯克利招生悖论 (1973)
- 问题:伯克利研究生院总体数据显示男生录取率高于女生,是否存在性别歧视?
- 数据:分系看,每个系女生的录取率反而高于男生(或持平)。总体差异源于女生更多申请竞争激烈的系。
- 因果图:性别 → 申请系别(中介)→ 录取结果,以及性别 → 录取结果(直接歧视路径)。
- 分析:要判断是否存在直接歧视,应该控制中介(系别),即比较同系内男女录取率。结果发现无歧视,甚至有利于女生。但要注意,如果存在未测量的中介-结果混杂(如居住地影响系别选择和录取),结论可能不同。这体现了中介分析的复杂性。
3.3 代数普及政策 (Algebra for All)
- 背景:芝加哥公立学校要求所有九年级学生修代数。初步评估显示总体成绩无显著提高。
- 中介:Guanglei Hong 提出,政策可能通过改变课堂环境(如混合能力教学)影响成绩。课堂环境是中介。
- 分析:直接效应(提高课程难度)为正,但间接效应(通过课堂环境)为负,两者抵消,导致总效应为零。后来的“双倍代数”政策(为低分学生提供额外代数课)改善了课堂环境,取得成功。
- 启示:中介分析解释了为何一项好政策可能失效,并指导了后续改进。
3.4 吸烟基因 (Mr. Big)
- 背景:2008年发现一个基因(rs16969968)与肺癌风险相关,同时也与吸烟行为相关。
- 问题:该基因是通过增加吸烟量(间接效应)致癌,还是通过其他生物途径(直接效应)致癌?
- 分析:VanderWeele 等利用中介分析发现,该基因的效应几乎全部是直接效应(即与吸烟行为无关),且与吸烟有交互作用(吸烟者风险更高,不吸烟者无风险)。
- 意义:这提示携带该基因者应特别避免吸烟,并可能需要更频繁的肺癌筛查。
3.5 止血带谬误 (Tourniquet Use)
- 问题:战场止血带能否提高生存率?一项观察研究发现,使用止血带的士兵与未使用的士兵相比,生存率无差异。
- 中介:止血带的作用可能是通过帮助士兵存活到达医院(中介)而影响最终生存。但研究只纳入了到达医院的士兵,相当于条件于中介(存活到达医院),这会导致对撞子偏差。
- 因果图:止血带 → 存活到达医院(中介)→ 最终生存,同时受伤严重程度影响止血带使用和存活。研究条件于中介(到达医院),打开了受伤严重程度与止血带之间的后门,引入偏差。
- 教训:中介分析需要警惕对中介的内生选择。
4. 概念关系图
CDE(m)"] --> Def1[固定 M=m] NDE[自然直接效应
NDE] --> Def2[固定 M=M0] NIE[自然间接效应
NIE] --> Def3[固定 X=0,改变 M=M1] end subgraph 估计公式 NDE_formula["NDE = Σ P(M|X=0) × ΔY|M"] NIE_formula["NIE = Σ ΔP(M|X) × Y|X=0,M"] end subgraph 假设 NoU[无未测量混杂
X-M, M-Y] end subgraph 实例 Berkeley[伯克利招生] SmokingGene[吸烟基因] Algebra[代数政策] Tourniquet[止血带] end %% 连接关系 NDE --> NDE_formula NIE --> NIE_formula NDE_formula --> NoU NIE_formula --> NoU NoU --> Berkeley NoU --> SmokingGene NoU --> Algebra NoU --> Tourniquet
5. 与前后的联系
- 与第1章的联系:中介分析涉及因果之梯的第三层(反事实),因为自然效应需要嵌套反事实(如 $Y_{1,M_0}$)。
- 与第3章的联系:中介变量在因果图中表现为链 $X \rightarrow M \rightarrow Y$,属于三种基本连接之一。
- 与第4章的联系:中介分析必须警惕混杂,尤其是中介-结果混杂,这需要后门准则来处理。
- 与第7章的联系:前门准则是中介分析的特例,其中我们利用中介来估计总效应。
- 与第8章的联系:自然直接效应和自然间接效应的定义本身就是反事实,因此需要第8章的三步法来计算。
6. 总结与重点
核心要点
- 中介变量 是解释“为什么”的关键,它揭示了原因到结果的内在机制。
- 线性模型 中,总效应可简单分解为直接效应(路径系数 $c$)与间接效应($a \times b$)。Baron-Kenny 方法虽流行,但局限性强。
- 非线性与交互 需要反事实定义:自然直接效应 (NDE) 和 自然间接效应 (NIE)。它们将中介固定在自然水平,从而分离出纯粹的直接和间接影响。
- 中介公式 提供了在满足无未测量混杂假设下,从观测数据估计 NDE 和 NIE 的方法。
- 历史案例 展示了中介分析在智力遗传、性别歧视、教育政策、遗传学和急诊医学中的广泛应用,也警示了常见错误(如条件于中介导致的对撞子偏差)。
- 警惕:中介分析需要清晰的因果图作为基础,且必须谨慎处理混杂和选择偏差。
常见难点
- NDE 与 CDE 的区别:CDE 将中介固定为某个常数,NDE 将中介固定在自然水平(即不处理时的值)。NDE 更符合直觉,因为它在实际中对应于“如果我们阻断间接路径,处理还会产生多少效果?”
- 嵌套反事实的理解:$Y_{1,M_0}$ 表示在 $X=1$ 但 $M$ 取值如同 $X=0$ 时的世界。这需要两步干预,容易混淆。
- 中介公式的条件:必须确保在给定 $X$ 下,$M$ 与 $Y$ 之间无未测量混杂。这是很强的假设,需要领域知识支持。
学习建议
- 画因果图:对每个中介问题,先画出完整的因果图,明确 $X$、$M$、$Y$ 以及可能的混杂。
- 区分总效应、直接效应、间接效应:用反事实语言写出它们的定义,并尝试用公式表示。
- 应用公式:用简单数值例子练习中介公式的计算,体会加权平均的含义。
- 阅读案例:重读伯克利招生、代数政策等案例,思考因果图如何揭示正确的分析方法。
- 联系实际:思考你研究领域中的“为什么”问题,能否找到一个可能的中介变量,并画出其因果图。
第9章将我们带入因果推断的更深层次——机制探索。掌握中介分析,不仅能回答“是否”,还能回答“如何”,使科学解释更加丰满。
《The Book of Why》第10章“Big Data, Artificial Intelligence, and the Big Questions”深度讲解
引言:回归初心,展望未来
第10章是全书的压轴章节,它将我们之前学习的因果推断概念与当前最热门的两个领域——大数据和人工智能——紧密结合起来,并探讨了更深远的哲学问题,如强人工智能、自由意志和道德机器人。珀尔在这一章中回归了他作为人工智能研究者的初心,指出因果推断是实现人类水平智能的关键。同时,他也对“大数据崇拜”提出了尖锐的批评:数据本身是愚蠢的,只有结合因果模型,才能从数据中提炼出真正的知识。
1. 大数据与因果推断
1.1 数据的局限性
- 核心观点:数据只记录关联,不记录因果。无论数据量多大,如果没有因果模型,我们无法回答“为什么”和“如果……会怎样”的问题。
- 例子:即使有所有用户的点击流数据,我们也不能确定是广告导致购买,还是购买倾向导致点击广告。这需要因果模型来区分。
- 大数据的作用:大数据并非无用,它可以在因果推断的最后一步——估计——中发挥重要作用,例如处理高维数据、进行精确匹配、克服维度灾难。但前提是已经有了因果模型和可计算估计量 (estimand)。
1.2 数据融合与可迁移性 (Transportability)
- 问题:我们经常有多个来自不同人群、不同环境的研究数据。如何将这些数据结合起来,回答一个在新环境中的因果问题?
- 定义:可迁移性是指,给定一个源人群的因果效应估计,能否将其应用于目标人群,并给出有效估计。
- 关键:不同人群可能存在差异,例如年龄分布、文化背景等。这些差异可以用差异变量 $S$ 表示,指向受影响的因素。例如,洛杉矶研究的年龄结构与阿肯色州不同($S$ 指向年龄)。
- 因果图方法:用因果图表示每个研究的特征(图10.2)。通过 $do$-演算,可以判断目标效应是否可迁移,以及需要哪些调整。
- 例子:在线广告效果估计。我们有洛杉矶、波士顿、旧金山、多伦多、檀香山的研究,各自有不同的特征(年龄、点击率等)。想估计在阿肯色州的效果。通过 $do$-演算,可以得出哪些研究的数据可直接使用,哪些需要调整,哪些完全不能使用。
- 意义:这为“外部有效性”问题提供了系统解决方案,使研究者能够充分利用已有数据,避免重复实验。
1.3 选择偏差的纠正
- 问题:研究样本可能不是目标人群的随机样本,例如只研究住院病人(伯克森悖论)。
- 方法:将选择过程建模为因果图中的一个节点($S$),箭头从影响选择的变量指向 $S$。然后利用 $do$-演算,可以判断是否可以通过观测某些变量来纠正偏差。
- 例子:止血带研究中,只分析了到达医院的士兵(条件于中介)。这引入了选择偏差。通过因果图可以识别出这种偏差,并指导如何收集额外数据来纠正。
2. 强人工智能 (Strong AI)
2.1 什么是强人工智能?
- 定义:具有人类水平智能的机器,能够理解、学习、推理、计划、解决问题,并具有意识(至少是表面上的)。
- 当前AI的局限:目前的AI(如深度学习)主要处于因果之梯的第一层(关联),能够发现模式,但不能理解原因。它们缺乏对世界的因果模型,因此无法进行干预和反事实推理。
2.2 因果模型是实现强AI的关键
- 透明性:深度学习模型是黑箱,无法解释其决策。因果模型(如因果图)是透明的,每一步推理都可追溯。
- 沟通能力:人类用因果语言交流(“你为什么这样做?”)。如果机器不能理解因果,就无法与人类自然对话。
- 学习能力:反事实推理使机器能从错误中学习,设想“如果当时做了不同选择,结果会怎样?”这是人类学习的重要方式。
2.3 自由意志与道德机器人
- 自由意志问题:如果世界是因果决定的(或随机的),那么自由意志是否存在?珀尔认为,自由意志可能是一种“错觉”,但这种错觉对人类至关重要,因为它使我们能够谈论意图和责任。
- 机器如何拥有自由意志? 机器不需要真正的自由意志,但需要模拟这种错觉。这可以通过在机器内部构建一个“意图生成器”和“自我反思”模块来实现。机器可以记录自己的“意图”,并基于反事实推理评估不同选择的后果。
- 道德机器人:基于因果模型,机器可以推理其行为的后果,从而区分善恶。例如,阿西莫夫的三定律是规则性的,容易导致矛盾;而基于因果推理的伦理系统可以根据后果灵活决策。
- 例子:机器人清洁工在清晨工作会吵醒主人。通过反事实推理(“如果我不在这个时间清洁,主人会睡得更久”),它可以学会调整行为。这种学习比单纯编程规则更灵活。
3. 概念关系图
4. 实例辅助
4.1 在线广告的可迁移性
- 问题:一家公司想在阿肯色州投放广告,但只有洛杉矶、波士顿等地的实验数据。每个地方的人群特征不同。
- 因果图:每个研究的差异变量(如年龄结构、点击率)指向图中相应的变量(图10.2)。
- 分析:通过 $do$-演算,可以确定:
- 波士顿的数据可直接迁移(差异变量不相关)。
- 洛杉矶的数据需要按年龄重新加权。
- 檀香山的数据需要更复杂的调整,甚至可能无法使用。
- 多伦多和旧金山的数据结合使用可得到准确估计。
- 结果:无需在阿肯色州进行新实验,就能估计广告效果。
4.2 机器人清洁工的学习
- 场景:机器人在主人睡觉时启动清洁,被主人批评“你不该吵醒我”。
- 因果模型:机器人内部有一个世界模型:清洁行为 ($X$) → 噪音 ($M$) → 主人醒 ($Y$)。同时,主人醒也受其他因素影响(如时间)。
- 反事实推理:机器人利用观测(主人醒了)更新其对世界状态的信念,然后模拟“如果我没有清洁 ($do(X=0)$),主人还会醒吗?”如果反事实结果表明主人可能不醒,则机器人学会避免在此时清洁。
- 意义:这种学习基于单一事件,而非大量重复,类似于人类的学习方式。
5. 与前后的联系
- 与第1-3章的联系:本章回顾了因果之梯的三个层次,强调当前AI主要在第一层,要实现强AI必须攀登到第二、三层。
- 与第4章的联系:可迁移性依赖于第4章的后门准则和混杂控制。
- 与第7章的联系:可迁移性分析的核心工具是第7章的 $do$-演算,它提供了判断可识别性的通用方法。
- 与第8章的联系:反事实学习是第8章反事实算法的直接应用,特别是三步法(吸收、行动、预测)。
- 与第9章的联系:道德机器人需要理解行为的直接和间接后果,这涉及中介分析。
6. 总结与重点
核心要点
- 数据是愚蠢的:大数据本身不能回答因果问题,必须与因果模型结合。
- 可迁移性:利用 $do$-演算,可以将不同研究的数据融合,应用于新环境,这是大数据时代因果推断的重要实践。
- 强人工智能需要因果推理:当前AI(深度学习)停留在关联层,要实现人类水平智能,必须赋予机器因果模型,特别是反事实能力。
- 自由意志与道德机器人:自由意志可能是一种错觉,但对人类道德至关重要。机器可以模拟这种错觉,通过反事实推理做出符合道德的决策。
- 透明性:因果模型提供透明性,使AI的决策可解释、可信任。
常见难点
- 可迁移性与外部有效性的区别:外部有效性通常指一个研究的结果能否推广到另一人群,但缺乏系统方法。可迁移性用因果图明确建模了人群差异,并提供了算法判断。
- 机器自由意志的模拟:机器没有真正的意识,但可以模拟意图和自我反思。这需要构建一个包含“自我模型”的因果图,使机器能推理自己的行为。
- 数据融合的复杂性:不同研究可能有不同的测量变量、不同的偏差。需要仔细建模差异变量,否则可能引入新偏差。
学习建议
- 回顾 $do$-演算:理解可迁移性的推导需要熟悉第7章的 $do$-演算规则。
- 思考实际问题:选择一个你感兴趣的领域(如教育、医疗),设想如何将不同研究的数据迁移到你的目标人群,画出因果图。
- 哲学思考:阅读有关自由意志和AI伦理的文献,结合本章观点,思考机器能否真正拥有道德。
- 展望未来:想象一个具有因果推理能力的机器人,它将如何改变我们的生活?有哪些潜在风险?
第10章将全书的因果推断理论提升到哲学和未来的高度。它提醒我们,因果革命不仅改变了科学方法,还将深刻影响人工智能的发展,甚至人类对自身的理解。