Engram-PEFT
English | [中文]
[!IMPORTANT] 这是一个 DeepSeek Engram 论文 (arXiv:2601.07372) 的 非官方实现。DeepSeek-AI 官方示例在这里。
![]()
![]()
Engram-PEFT 是一个高性能、100% 对齐论文的 DeepSeek Engram 架构实现。它提供了一个类 PEFT 接口,可将条件记忆 (Conditional Memory) 注入任何基于 Transformer 的大语言模型,同时通过显式 train_mode 支持纯 Engram、Adapter 叠加和全参数微调三类工作流。
Engram 使用稀疏检索机制将 静态知识存储 与 动态推理 解耦,允许模型在不增加推理 FLOPs 或干扰核心逻辑的情况下,扩展其实际记忆。
🚀 快速开始
安装
pip install engram-peft
如果您需要运行示例脚本或进行开发,请安装开发依赖:
# 使用 uv (推荐)
uv sync --all-groups
# 使用 pip
pip install -e ".[dev]"
NPU (昇腾) 支持:如需在华为昇腾 NPU 上训练,请安装 torch-npu:
pip install torch-npu --index-url https://repo.huaweicloud.com/repository/pypi/simple
bfloat16——请在 EngramConfig 中设置 engram_dtype="float16"。
NPU 分布式训练(torchrun DDP、DeepSpeed ZeRO‑1/2)使用内置的后端检测:
from engram_peft.utils.device import get_distributed_backend
backend = get_distributed_backend() # NPU 返回 "hccl",CUDA 返回 "nccl"
5 分钟上手示例
from transformers import AutoModelForCausalLM, AutoTokenizer
from engram_peft import EngramConfig, get_engram_model
# 1. 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T")
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T")
# 2. 注入 Engram 层 (对齐 arXiv:2601.07372)
config = EngramConfig(target_layers=[2, 11, 20])
model = get_engram_model(
base_model,
config,
tokenizer,
train_mode="engram_only",
)
# 3. 快速检查可训练参数
model.print_trainable_parameters()
# trainable params: ... (backbone: 0, engram: ...) || all params: ... || trainable%: ...
YAML 配置驱动训练 (CLI)
除了 Python 脚本,您也可以直接通过 YAML 配置文件触发训练,无需编写任何代码:
# 1. 生成包含完整注释的配置模板
engram-peft config-template --output training_config.yaml
生成的 YAML 文件包含五个核心区块:
- model_name_or_path: 基础模型路径 or ID。
- engram_config: Engram 层的核心超参数。
- lora_config: (可选) PEFT LoRA 设置,用于混合适配。
- training_args: 标准的 transformers.TrainingArguments 训练参数。
- data_args: 数据集设置与分词逻辑。
2. 使用配置文件(或极简的 examples/config.yaml)启动训练
engram-peft train --config training_config.yaml
3. 训练后推理
CLI 会在您的 output_dir 中自动生成一个随时可用的 inference.py 脚本:
uv run python outputs/tinyllama-lora-engram/inference.py
4. 在运行时动态覆盖特定参数
engram-peft train --config training_config.yaml --overrides "training_args.learning_rate=5e-5"
📊 性能对比
| 方法 | 额外参数总量 | 训练速度 (s/step) | 训练集 Loss | 验证集 Loss | 峰值显存 (JSON) |
|---|---|---|---|---|---|
| LoRA (r=16) | ~2.25 M | 0.2738 s | 1.231 | 0.9890 | 8.07 GB |
| Engram-PEFT | 545.4 M | 0.2961 s | 1.263 | 1.0165 | 9.38 GB |
| LoRA+Engram | ~547.7 M | 0.3360 s | 1.214 | 0.9656 | 10.33 GB |
| Full Finetune+Engram | ~545.4 M | 0.3818 s | 1.111 | 1.0944 | 15.32 GB |
[!TIP] 性能洞察:在最新的基准测试(Test 8 & 9, TinyLlama-1.1B, 3000 步)中,LoRA+Engram 实现了最佳的收敛效果(最低验证集 Loss),相比独立 LoRA 提升了约 2.3%,相比 Engram 提升了约 5.0%,相比 Full Finetune+Engram 提升了约 12.2%。Engram-PEFT 提供了 240 倍的参数容量 (545M) 用于知识存储,且延迟增加极低。推荐使用 LoRA+Engram 以同时获得结构微调与高容量稀疏记忆。Full Finetune+Engram 虽然内存消耗更大,但仍表现出竞争性能,不过需要显著更多的 GPU 资源,且存在潜在的过拟合倾向。
Loss 曲线对比
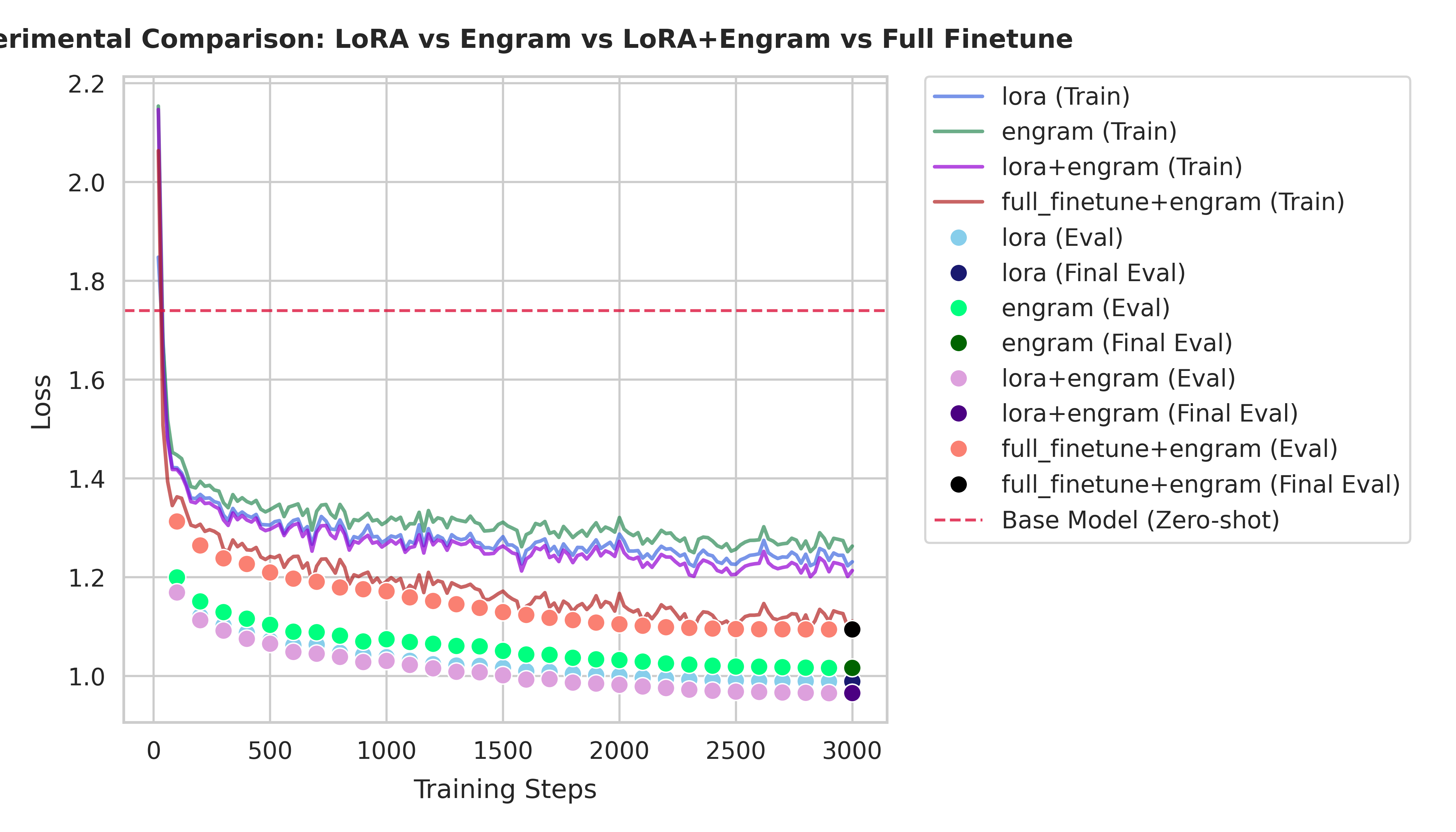
* Engram 采用稀疏检索机制;每步仅有极小比例(约 1%)的参数被激活并接收梯度更新。如需在您的硬件上复现这些基准测试,请运行 uv run python examples/compare_engram_lora.py --all。关于性能、计算开销和显存占用的详细对比分析,请参阅 性能对比分析报告 (英文)。
🛠 特性
- 100% 对齐论文:实现了附录 A 表 5 的参数以及 DeepSeek 官方的门控/哈希逻辑。
- CPU 预取与预计算:
EngramDataCollator在 CPU 上预先计算多头哈希索引。配合num_workers > 0可实现与训练并行的异步预取,确保 GPU 零哈希开销。 - 分词器压缩 (Tokenizer Compression):内置 NFKC 和小写归一化,实现 23% 的词表缩减。
- 跨模型权重迁移:独有特性(详见
weight_transfer.py),支持通过语料库的字符级对齐,在不同模型(如 Llama 到 Qwen)之间迁移 Engram 权重——实现知识的“回收再利用”。 - 零侵入性:通过 forward hook 注入;无需修改基础模型架构源码。
- 类 PEFT API:提供
print_trainable_parameters()和save_pretrained()等熟悉的方法。 - 断点续训 (Checkpoint Resume):
EngramTrainer完全支持trainer.train(resume_from_checkpoint=True)无缝恢复训练,正确从复合 checkpoint 中恢复 LoRA adapter 和 Engram 权重。 - 显式训练模式:支持
train_mode="engram_only"、"preserve_trainable"和"full_finetune",更易理解和调试。 - 联合训练 (LoRA+Engram): 支持 Adapter 叠加。可在单个模型中同时注入 LoRA 进行结构微调和 Engram 进行稀疏知识检索。
- 分层优化器控制:可分别为 backbone、Engram dense 层和 Engram sparse embedding 配置不同优化器。
- 命名适配器 (Named Adapters):完全兼容 PEFT 风格的 Adapter 管理(add/set/unload),支持多领域知识包并行管理。
- 自动化训练流程:内置
EngramTrainer,自动处理稀疏 Adam 优化、梯度管理与学习率倍率同步。 - YAML 驱动的 CLI:完全声明式的训练工作流,支持 YAML 配置与动态参数覆盖。
- 自动化推理脚本生成:CLI 会在训练完成后自动生成可立即运行的
inference.py脚本,方便快速验证。 - 主流模型开箱即用模板:提供 Qwen 3.5-4B、Ministral-3-3B 和 Gemma-4-E2B 的训练与推理脚本,内置量化支持。
- 多模态与主流架构深度适配:原生支持复杂封装架构下的递归层定位,兼容多模态模型特有的嵌套配置(text_config)同步,实现对 Qwen、Gemma 等新架构的无缝支持。
- Hugging Face Hub 集成:支持通过
push_to_hub上传适配器,并通过from_pretrained直接从 Hub ID 加载,与 PEFT 生态深度对齐。 - TRL & SFTTrainer 兼容性:原生提供
EngramCompatibleSFTTrainer,自动处理模型准备、哈希预计算及稀疏梯度裁剪,实现无缝的指令微调。 - 量化支持:原生兼容 bitsandbytes (4-bit/8-bit) 和 GPTQ 模型。智能 dtype 检测确保 Engram 层自动与主干网络的
compute_dtype对齐。 - 统一设备后端:自动检测并支持 CUDA、NPU(昇腾) 和 CPU,提供统一的 AMP、GradScaler 和分布式后端检测(
get_distributed_backend()对 NPU 返回"hccl",对 CUDA 返回"nccl")。 - 分布式训练(DDP & DeepSpeed):完全兼容
torchrun(DDP)和 DeepSpeed ZeRO-1/2,同时支持 CUDA 和 NPU。DDP 下支持分布式稀疏 Embedding;DeepSpeed 模式下自动回退为稠密 Embedding 以兼容 ZeRO 优化器。
📖 文档
完整详情请参阅我们的文档: - 教程: 快速上手指南和领域知识注入。 - API 参考: 详细的类和函数文档。 - 论文对齐: 我们如何对齐 DeepSeek 的研究。
训练模式速查
# 仅训练 Engram
model = get_engram_model(base_model, config, tokenizer, train_mode="engram_only")
# 保留现有可训练参数(如 LoRA)
model = get_engram_model(model, config, tokenizer, train_mode="preserve_trainable")
# Engram + 全参数微调
model = get_engram_model(base_model, config, tokenizer, train_mode="full_finetune")
分层优化器示例
from torch.optim import AdamW
from engram_peft import get_optimizer
optimizer = get_optimizer(
model,
backbone_learning_rate=5e-5,
engram_dense_learning_rate=4e-4,
engram_sparse_learning_rate=2e-3,
backbone_optimizer=AdamW,
)
🎯 引用
如果您在研究中使用此实现,请引用 DeepSeek 的原始论文:
@article{deepseek2026engram,
title={Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models},
author={DeepSeek-AI},
journal={arXiv preprint arXiv:2601.07372},
year={2026}
}
🤝 贡献
我们欢迎各种形式的贡献!请参阅我们的 贡献指南 了解关于分层开发工作流 (L1-L4) 和测试标准的详细信息。
📄 开源协议
Apache License 2.0。详情请参阅 LICENSE。